
Abb. 1: Vergleich der relativen Häufigkeiten dreier Wörterbücher

Die quantitativ-deskriptive Analyse, von der hier gehandelt werden soll, verkörpert nur einen kleinen Ausschnitt aus dem weiten Feld der Textanalyse. Sie ist nicht ganz so alt und ursprünglich wie ihre interpretierende, subjektive, auch "intuitiv" genannte Schwester, geht aber wie diese auf antike Wurzeln zurück. Ihre Besonderheit ist die Verwendung der Mathematik, mit der von alters her der Anspruch auf intersubjektive Überprüfbarkeit verknüpft ist. Daß dieser letztere freilich ein ums andere Mal auf der Strecke blieb, als die Quantifizierung auf mitunter groteske Weise zum Vehikel inhaltlicher Inferenz gepreßt wurde, sei hier nur am Rande vermerkt.
Neben dem modernen linguistischen Interesse, Mechanismen, Stand und Entwicklungstendenzen einer Sprache zu beschreiben, stand - und steht - literarische Kriminalistik im Vordergrund textanalytischen Fragens. Die Literaturgeschichte kennt zahlreiche Exempla ungeklärter Autorschaften und Datierungen, Probleme, für die beim Versagen anderer Mittel regelmäßig die Quantifizierung der strittigen Dokumente als Remedium herangezogen wurde. Indessen kann auch eine Bilanz solcher Bemühungen nur festhalten, daß die einschlägig tätigen Wissenschaften keinen Konsens über das zweckmäßige Objekt, geschweige denn über die Methode der Quantifizierung erzielt haben.
Hinter dem Einsatz der quantifizierenden Analyse steht naturgemäß die Überzeugung, daß sich die Individualität eines Schreibenden als "Regelhaftes" im Geschriebenen wiederfinden lasse: Vorlieben und Abneigungen etwa im aktiven Wortschatz und in der Wortbildung, in der Fügung von Junkturen, in der Konstruktion von Hypotaxen, in der Einleitung von Sätzen und Abschnitten, überhaupt in der Untergliederung von Texten u.v.a. bis hin zum zyklischen Wiederkehren der gleichen Formulierung desselben Gedankens. Diese nur scheinbar triviale These ist - wiewohl sie nicht ernsthaft bestritten werden kann - zugleich auch die Crux des Ganzen, hat sie doch immer wieder zur Behauptung eines "literarischen Fingerabdrucks" geführt. Mit ihr ist freilich ein Schritt zu weit getan: Die Annahmen, daß der Sprachgebrauch eines Autors wie ein Fingerabdruck übers ganze Leben hinweg unveränderlich bleibe, daß er sich ferner von dem eines jeden anderen zweifelsfrei unterscheide und daß er sich schließlich ohne größeren Aufwand nachweisen lasse - diese Implikationen der Analogie dürfen mit Fug und Recht als fahrlässig ad acta gelegt werden.
Es bleibt mithin festzuhalten, daß beobachtbare, meß- und beschreibbare Gewohnheiten in der Sprache eines Autors einerseits nicht in Frage gestellt werden können, daß jedoch andererseits die Extrapolation der hierüber gewonnenen Erkenntnisse, d.h. die Behauptung einer Konsistenz jener Gewohnheiten über das untersuchte Textkorpus hinaus, problematisch bleiben muß - eine Irrtumswahrscheinlichkeit, die sich einer genauen Bezifferung stets entziehen wird. Mit anderen Worten: Die literarische Kriminalistik wird sich damit abfinden müssen, vom Instrumentarium der Textquantifizierung nur Indizien, keine Beweise gewärtigen zu können.
Vor dem Hintergrund dieser Kautel umreiße ich im folgenden meine bisherige Beschäftigung mit der Frage, was und wieviel an Meß- und Beschreibbarem sich auf einfache Weise in Texten aufspüren und für die Identifizierung des Autors nutzen läßt. "Einfach" sollte in diesem Zusammenhang dreierlei bedeuten:
Das Gattungsspektrum der bisher analysierten Textgruppen - darunter deutsche, französische, englische und lateinische - reicht vom Märchen über Belletristik, Philosophie und politische Pamphletistik bis zur Geschichtsschreibung und Politikwissenschaft. Die Größe der Texte schwankt, doch darf sie innerhalb einer Vergleichsgruppe nicht erheblich streuen; eine Menge von ca. 20 DIN-A4-Typoskriptseiten sollte als untere Grenze nicht unterschritten werden; bestimmte Analyseansätze verlangen ein noch wesentlich größeres Volumen. Aus den bislang erprobten, sehr zahlreichen Verfahren skizziere ich im folgenden nur einige wenige derer, die sich über alle Untersuchungsgruppen hinweg als aussagefähig erwiesen haben; die zur Illustration exemplarisch herangezogenen Zahlen und Graphiken sind dem Vergleich dreier kleiner französischer Texte entnommen. Als EDV-Werkzeug der Quantifizierung findet überwiegend TUSTEP Verwendung, dessen Systemcharakter hierfür von einzigartigem Wert ist: Kaum ein Frageansatz ließ sich nicht in kürzester Frist programmtechnisch realisieren, wo es mit anderen Mitteln - aufgrund der meist sehr schwierigen Formalisierung von Sprache - wochen- und monatelanger Entwicklungsarbeit bedurft hätte.
Bereits bei der hier vorwaltenden geringen Textmenge (je ca. 20 Seiten) fällt ins Auge, daß die Summe der Differenzen zwischen den Texten B und C kleiner ist als die der anderen Vergleiche; im Regelfall verstärken sich die Unterschiede noch bei wachsender Textgröße. (Diese Beobachtung der Affinität von B und C bestätigt sich im folgenden immer wieder, weshalb ich künftig nicht mehr eigens darauf hinweise.)Abb. 1: Vergleich der relativen Häufigkeiten dreier Wörterbücher
Experimente mit der Filterung der Berechnung, d.h. Berücksichtigung nur der Einträge, die bestimmte Bedingungen (vgl. etwa Anm. 2) erfüllen, erbrachten kein höheres Signifikanzniveau. Im Gegenteil: Da solche Eingriffe das statistische Korpus schmälern, lassen sie lediglich die Irrtumswahrscheinlichkeit überproportional ansteigen.
Ein anderes Experiment erwies sich hingegen als erfolgversprechend: die Auswertung von n-Tupeln von Wörtern, d.h. von Einträgen, die nicht mehr von einzelnen Wörtern, sondern von Wortverbindungen auf Satzebene gebildet werden. Nachteil dieses Analyseverfahrens ist, daß erst die Auswertung sehr großer Textkorpora überzeugende Ergebnisse erbringt.
Ein weiteres probates Mittel ist die "Type-Token-Ratio" (TTR), bei der es sich i.w. um eine Kenngröße für die Breite des Wortschatzes in einem Text handelt. Unter den Möglichkeiten ihrer Berechnung sei hier die einfachste herausgegriffen: die Division der Zahl der in einem Text insgesamt vorkommenden Wörter (Tokens) durch die Zahl der darin enthaltenen verschiedenen Wörterbucheinträge (Types). Dieses simplifizierende Verfahren hat hier seine Berechtigung, denn da bei wachsender Textgröße der verwendete Wortschatz nicht linear mitwächst (Zipf's Law), wurde zur Vermeidung bestimmter Probleme die Berechnung auf der Grundlage standardisierter Textgröße (6332 Tokens in allen drei Texten) angestellt.
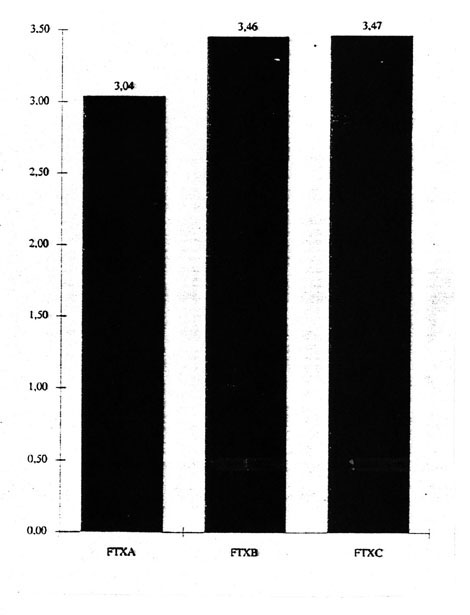
Abb. 2: Type-Token-Ratio (TTR), standardisierte Größe
Altbekannt ist auch die Ermittlung durchschnittlicher Satzlängen - meist nach Silben, seltener nach Wörtern oder Zeichen kalkuliert, obwohl es nach aller bisheriger Erfahrung für die Relationen nahezu bedeutungslos ist, welches Zählkriterium gewählt wird. Auch sie läßt sich maschinell leicht berechnen und erbringt oft überraschend deutliche Ergebnisse.
Indessen ist mit der Ermittlung solcher Durchschnittswerte ein Unsicherheitsfaktor verbunden: die jeder Mittelwertberechnung zugrundeliegende Nivellierung der Charakteristika eines Häufigkeitsverlaufs. Differenzierter und aussagefähiger sind deshalb Häufigkeitsprofile, die maschinell nicht minder leicht zu errechnen sind.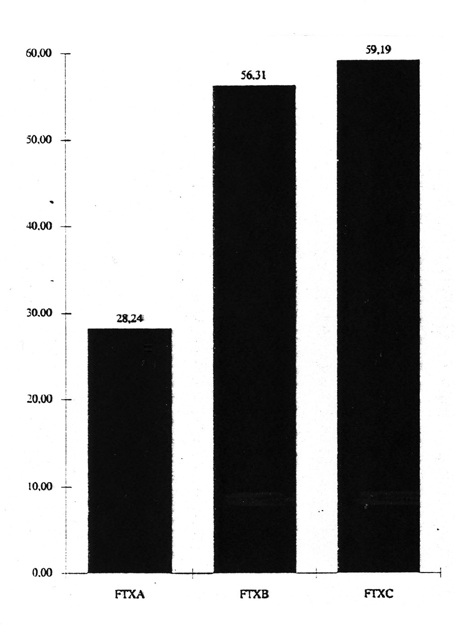
Abb. 3: Mittelwerte Silben/Satz
Daß sich analog dazu auch vieles andere auf Absatz-, Satz- und Wortebene quantifizieren läßt, was bemerkenswert eindeutige Hinweise auf Unterschiede und Übereinstimmungen von Textproben zutage fördern kann, sei hier nur angedeutet.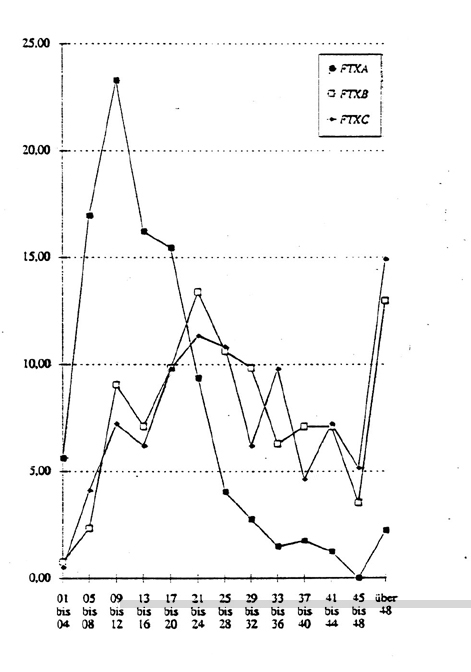
Abb. 4: Häufigkeitsprofil Silben/Satz
Im selben Zusammenhang habe ich auch verschiedene Strategien des selektiven Zugriffs auf die Häufigkeiten von Worttypen auf Satzebene erprobt. Alleinige Voraussetzung sollte deren formale Bestimmbarkeit über Präfixe, Infixe, Suffixe, Wortzusammensetzungen, Flexionsendungen oder auch bloß über frei definierte Laute und Lautkombinationen sein. Die Ergebnisse fielen dabei freilich um so indifferenter aus, je geringer der Anteil des jeweiligen Worttyps am Gesamtwortschatz der drei Texte war. Im ganzen gelang es - wie bei ähnlichen Versuchen im Wörterbuchvergleich - nicht, ein ubiquitär verwendbares Filter zu finden, das bessere Indizien als die schon demonstrierten hätte abgeben können. Auch hier gilt überdies, daß die Verringerung des statistischen Korpus die Irrtumswahrscheinlichkeit unverhältnismäßig erhöht, was die Aussagekraft eines scheinbar schlagenden Ergebnisses bis zur Unbrauchbarkeit diffundieren läßt.
Ein weiterer vielversprechender Ansatz ist die Berechnung eines Kontingenzkoeffizienten für die Abhängigkeit von Satzlängen untereinander. "Kontingenz" soll hier im statistischen Sinne ein Maß sein für jede Abweichung des Auftretens der Satzlängen von derjenigen Abfolge, die unter der Annahme stochastischer Unabhängigkeit zu erwarten wäre. Der Text wird zu diesem Zweck als Abfolge von "kurzen" und "langen" Sätzen untersucht (wobei der Median aller Satzlängen das Kriterium der Unterscheidung von "kurz" und "lang" abgibt) und geprüft, ob das Auftreten der Satzlängen einer Gesetzmäßigkeit unterliegt: Wäre dies nicht der Fall, müßten gleichnamige Satzpaare (kk & ll) annähernd ebensooft auftreten wie ungleichnamige (kl & lk). Der als Quotient zwischen der Differenz und der Summe der gleichnamigen und ungleichnamigen Matrixelemente errechnete Kontingenzkoeffizient müßte demzufolge im Bereich ± 0 % liegen. Ältere Untersuchungen von W. Fucks ergaben jedoch für alle von ihm analysierten Texte positive Werte, womit die These von einer "Anziehungskraft" von Satzlängen untereinander gestützt wäre. In der Tat trifft dies bei der hier vorgestellten Vergleichsgruppe französischer Texte auch für Probe A zu, überraschenderweise jedoch nicht für B und C: Deren Werte liegen beide deutlich im negativen Bereich!
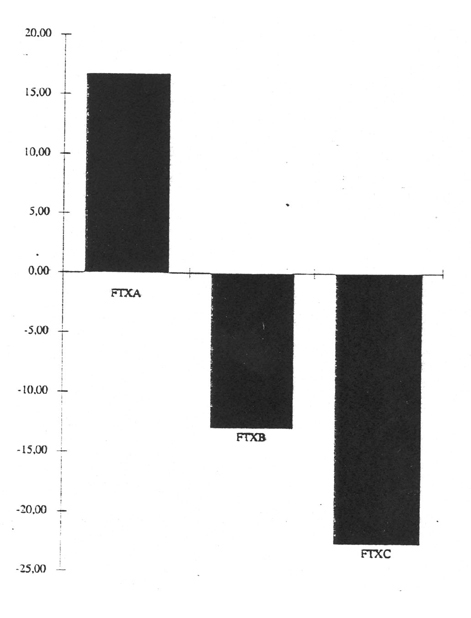
Abb. 5: Kontingenzkoeffizient Satzlängen nach Buchstaben/Satz
Zum Abschluß dieser Skizze verdient noch ein selbst entwickeltes Turbo-Pascal-Programm erwähnt zu werden, das Texte auf der Grundlage eines Wortschatzvergleichs in den Einzelsätzen in Relation zueinander setzt. Weil dabei jeder Satz in der Quelldatei nach vorzugebenden Optionen mit jedem Satz der Vergleichsdatei verglichen werden muß, stellt dieses Programm höchste Anforderungen an die Leistungsfähigkeit der Hardware; außerdem ist leicht ersichtlich, daß nur kleine Textmengen (bis ca. 30/40 Seiten je Textprobe) in noch vertretbaren Zeiträumen bewältigt werden können. Der Aufwand lohnt gleichwohl, weil das Verfahren bemerkenswerte Ähnlichkeiten in den Formulierungen zweier Texte aufzudecken vermag. Das Vergleichsergebnis - eine Dateiausgabe jener "Parallelstellen" - läßt sich seinerseits nach mehreren Kriterien quantifizieren, was nach allen bisherigen Erfahrungen ebenfalls vorzügliche Hinweise auf die Zusammengehörigkeit verwandter Texte ergibt.
2. Beispiele solcher Selektivität sind: Übersichten über die in allen Texten
oder über die in nur in zweien oder in einem Text belegten Einträge, über
nur die mit einer bestimmten Minimalhäufigkeit vertretenen Einträge, ggf.
nicht alphabetisch, sondern nach Häufigkeiten sortiert usw.
zurück
3. Die Auszüge sind den folgenden Büchern entnommen:
Einen besonderen Hinweis verdient der Befund, daß die
beiden Texte von Siegfried 26 Jahre auseinander liegen - eine
bemerkenswert große Zeitspanne, in der der Autor seiner
Sprache und seinem modus scribendi treu geblieben ist.
zurück
aus: Protokoll des 49. Kolloquiums über die Anwendung der EDV in den Geisteswissenschaften am 7. Juli 1990