
 (1)
(1)
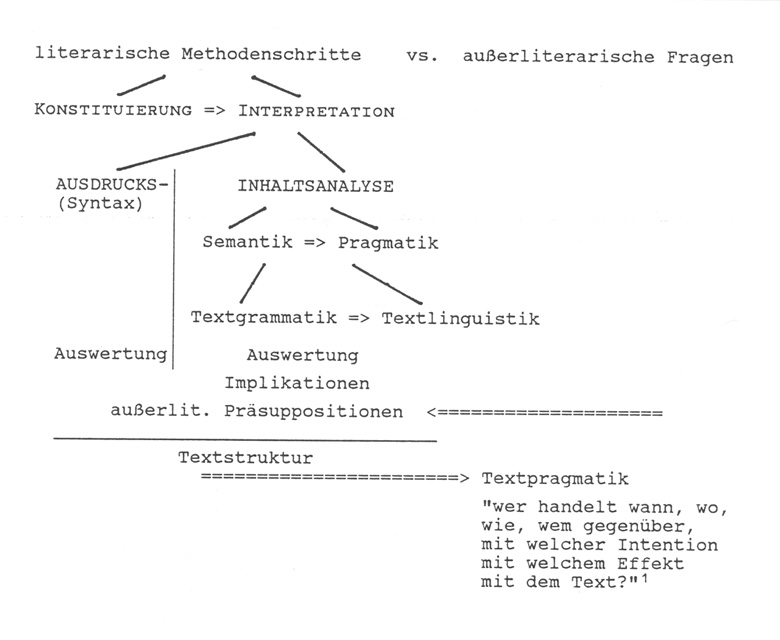
Das methodische Gesamtkonzept sieht zunächst eine ausführliche literarische Analyse des gegebenen Textes vor und will dann - auf der Basis der gewonnenen Erkenntnisse - auch Rückschlüsse auf außerliterarische Fragen ziehen (vgl. zur Textpragmatik). Bevor eine wissenschaftliche Deskription und Interpretation durchgeführt werden kann, müssen vorbereitende Analysen durchgeführt werden, hier unter dem Terminus "Konstituierung des Textes" zusammengefaßt: Textkritische Fragen sind zu klären (Editionsphilologie), eine wissenschaftlich begründete Arbeitsübersetzung ist zu erstellen, der Text ist nach "Äußerungseinheiten" zu gliedern (2), bei biblischen Texten ist ebenfalls die Frage der Literarkritik häufig sehr wichtig, also die Frage nach sekundären Überarbeitungen einer vorgegebenen Textfassung, damit auch die Frage an den Interpreten, ob er die Endversion oder die Ursprungsversion des Textes analysieren will.
Ist die zur Interpretation ausgewählte Textschicht in der beschriebenen Weise vorbereitet, so ist - analog der Zeichendefinition - die Interpretation streng nach zwei Aspekten zu trennen:
- Eine lediglich an den Zeichenträgern orientierte Ausdrucks-Syntax beschränkt sich darauf, Position und Distribution der Zeichenformen zu analysieren. Gerade mit Hilfe des Computers ist eine völlig inhaltsfreie Morphologie, die allerdings in den gängigen Grammatiken noch nicht vorgesehen ist, erstellbar. Sie ist hier aber auch nicht unser Thema, stattdessen
- sollen mit dem
Datenbankprogramm JOSEF die auf verschiedenen Ebenen gesammelten
Daten zur Inhaltsanalyse bereitgestellt werden:
- Die Semantik ist in diesem Gesamtkonzept im Sinne einer Satzsemantik verstanden. Zugleich ist für sie charakteristisch, daß sie die realisierten Bedeutungen so wörtlich wie möglich faßt, auch dann, wenn ungewohnte, ja schwierige, aber doch noch verstehbare Idiome im Spiel sind.
- Die Pragmatik hat den literarischen Kontext als Arbeitsbereich, den Zusammenhang von Äußerungseinheiten innerhalb eines Textes. Es sollen die vielfältigen Mechanismen beschrieben werden, durch die ein Kontext gebildet wird.
Die zweite Unterabteilung: Textlinguistik entledigt sich auch der zweiten Restriktion der Semantik. Es wird der gegebene Wortsinn in vielfältiger Weise kritisch analysiert, was in aller Regel zur Folge hat, daß das, was der Text meint, neu zu formulieren ist. Die Differenz von Wortsinn und gemeintem Sinn, der man auf diese Weise ansichtig wird, kann in bezug auf stilistische Effekte ausgewertet werden.
Die dritte Abteilung, die Textpragmatik, ist auf der Basis der geschehenen literarischen Beschreibung nun in der Lage, das zu rekonstruieren, was der Text nicht formuliert, was er aber offenbar impliziert. Es werden nun also die Leerstellen des Textes ausfindig gemacht. Eine weitere Stufe besteht darin, daß das beschrieben wird, was für Autor wie für Textempfänger problemlos zu sein scheint, also die Präsuppositionen. Bis hierher ist die Analyse literarisch orientiert gewesen, die Textstruktur wurde sehr sorgfältig erhoben. Ab jetzt geht die Untersuchung in den außerliterarischen Bereich hinein und versucht, Rückschlüsse auf die Intention des Autors wie auf die zu vermutenden Effekte beim Textempfänger anzustellen.
3. Inhaltsinterpretation
Für das Datenbankprogramm stellen sich vorbereitend drei verschiedene Aufgaben:- Beschreibung der materialen Textbasis, ihrer Auswahl und Vorbereitung für die Verwendung im Datenbankprogramm. Beschreibung ihrer internen Strukturmerkmale (Morphe) als Grundbedingung der späteren Adressierung (ist Feld der erwähnten rein ausdruckssyntaktisch orientierten Morphologie).
- Beschreibung des "interpretatorischen Überbaus".
- Beschreibung der einzelnen Analyseebenen.
- Beschreibung des Kategorienensembles, das auf jeder Ebene zur Anwendung kommt.
- Beschreibung der Abspeicherung (Verbindung von Interpretationsbegriff, auf zuvor gewählter Interpretationsebene, mit einem der Segmente der materialen Textbasis).
4. Analyseebenen
Die Textsegmentierungen, die aufgrund zuvor gewählter Betrachtungsperspektiven am Text vorgenommen werden, bauen in folgender Weise streng aufeinander auf: "Semem" (= Sm, = Einzelbedeutung), "Semem-Gruppe", "Äußerungseinheit" (= ÄE) steht für die Semantik. Die folgenden Ebenen spezifizieren den Gesamtbereich der Pragmatik: Textgrammatik, Textlinguistik, Textpragmatik. "E" steht dabei je für eine "kommunikative Einheit". Sie kann nach den gleichen Merkmalen befragt werden, die für einen "Satz" (= phrastische ÄE) gelten.Abbildung 2:
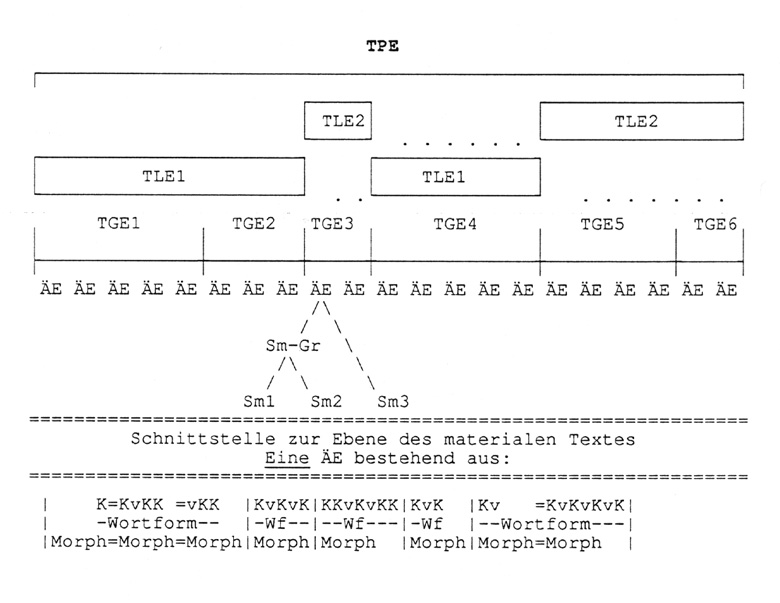
Die ganze Interpretation, d.h. die Anwendung der vielfältigen Begriffe, hat sich nach diesen Ebenen zu richten. Die Ebenenbestimmung ist vorrangig vor der Einzelanwendung von Begriffen und der damit verbundenen Adressierung von Partien der zugrundeliegenden materialen Textbasis. Der Interpret muß sich also fragen:
- Soll die Analyse im Rahmen der Semantik geschehen, d.h. innerhalb einer einzelnen ÄE und damit so, daß der Wortsinn gemeint ist (nicht irgendeine Form von übertragener Bedeutung)?
- Will ich im Rahmen der Pragmatik, und da in der ersten Untergliederung (= Textgrammatik), zwar noch beim Wortsinn bleiben, nun aber den Zusammenhang der ÄEen betrachten, insofern er durch explizite sprachliche Signale hergestellt wird? Der Text wird hierbei als lineare Abfolge textgrammatischer Einheiten betrachtet.
- Will ich in der zweiten Untergliederung der Pragmatik (= Textlinguistik) nun auch die verschiedenen Formen des übertragenen Sprachgebrauchs analysieren und mit diesen neuen Kenntnissen neu fragen, ob sich auch die Kommunikationseinheiten anders darstellen? Ergebnis ist - nicht die lineare Abfolge, sondern - die Verzahnung von mehreren textlinguistischen Einheiten (TLE), die ihrerseits genau sich auf zuvor definierte textgrammatische Einheiten (TGE) beziehen, die selbst auf den Grenzen für Äußerungseinheiten (ÄE) aufbauen.
- Die letzte Beschreibungsebene ist dann die textpragmatische Einheit (TPE). In der Einzeltextanalyse wird diese Beschreibung mit der Gesamtbeschreibung des Textes als ganzem zusammenfallen. Daher lohnt es sich nicht, hierfür im Computer auch eine eigene Analyseebene vorzusehen (da - im Rahmen des Einzeltextes - die eine TPE nicht mehr sich von einer anderen abgrenzt).
5. Die Arbeit mit dem Datenbankprogramm
Die Fülle der bis jetzt vorgestellten Analyseebenen und der in diesem Protokoll nicht darstellbaren Analysekategorien dürfte zur Genüge deutlich gemacht haben, daß die Arbeit damit eine interne Affinität zum Modell "Datenbank" hat. Die von der Datenbank verwalteten Textsegmente sind von sehr unterschiedlicher Größe. So kann es geschehen, daß ein einzelner Buchstabe mit einer sehr ausführlichen Analyse verbunden wird. Solche Zuordnungen lassen sich in einer sequentiellen Datei nicht mehr sinnvoll durchführen. Die Datenbank erlaubt damit auch, Textsegmente ganz unterschiedlicher Dimension zu beschreiben. Ein weiterer Aspekt: Das vorgestellte Interpretationssystem ist zwar sehr transparent konstruiert, ist zugleich aber in sich doch so komplex, daß selbst "kompetente" Benutzer dankbar für eine vorgegebene Benutzerführung sind, die sie davon entlastet, bei jedem einzelnen Datensatz mit höchster Aufmerksamkeit und danebengelegtem Handbuch mit Schaubildern die Eingaben zu tätigen.- Analyse: Der Text wird in einzelne Datensätze verwandelt.
Das Datenbankprogramm nimmt den Terminus "Analyse" ernst: Je nach Analyseebene wird der Text in kleinere oder größere Teile aufgelöst und dann mit einem metasprachlichen Terminus versehen. - Grammatikreservoir
In diesem Stadium ist also der Text verwandelt in ein großes Konglomerat von grammatischen Analysen. Es kann - bezogen auf den untersuchten Text - dessen grammatische Struktur auf den Ebenen von Semantik und Pragmatik höchst differenziert wieder abgerufen werden. Mit diesem Reservoir ist es möglich, die interne Schlüssigkeit der abgespeicherten Analysen nochmals zu überprüfen. Der Zwang, sich bei der Analyse bewußt zu machen, auf welcher Ebene die Analyse zu geschehen hat, verhindert, daß man dabei unbedacht Opfer einer Ebenenverwechslung wird. - Kombinationsabfragen
Wenn nun für die Bedeutungsanalyse Grammatikabspeicherungen bis zur Ebene des gesamten, geschlossenen Textes vorliegen, dann ist auch die Möglichkeit gegeben, kombinierte Abfragebedingungen zu formulieren, die Befunde mehrerer Ebenen miteinander verbinden, und nach Datensätzen zu fragen, die beiden (oder mehreren) Bedingungen Genüge leisten. br>Die Auswertung der abgespeicherten Analysen im Datenbankprogramm JOSEF führt auf sehr differenzierte Modelle für Sprechverhalten. Sobald sie mit empirischer Fundierung extrapoliert sind, sind ganz wesentliche weitere pragmatische Erkenntnisse gewonnen. Sie lassen besser verstehen und typisieren, was in kommunikativen Handlungen an Strategien üblicherweise eingesetzt wird. Es gibt sich damit dann auch ein neues Kriterium für kreativen Sprachgebrauch, der dann vorliegt, wenn auf solche breit belegten sprachlichen Handlungsmodelle weitgehend verzichtet wird.
An dieser Stelle liegt die Schnittstelle zwischen differenzierter textwissenschaftlicher Beschreibung und dem Bereich der "Kognitiven Psychologie" bzw. "Künstlichen Intelligenz". Der Übergang vom einen Bereich in den anderen läßt sich so organisch gestalten. Es liegen keine Welten mehr dazwischen. Dem interdisziplinären Gespräch ist also eine textwissenschaftliche Methodik im skizzierten Sinn sehr förderlich. - Synthese: Differenziertes Gesamtbild des Textes
Nach der "Analyse" kann nun die Synthese folgen. Die Verwandlung des Textes in ein Grammatikreservoir ist lediglich als willkommenes Zwischenstadium anzusehen. Der eigentliche Zweck, zu dem das Programm und zuvor schon die Methodik entwickelt worden waren, liegt in der Beschreibung des gesamten Textes, die nun im Sinne eines differenzierten Gesamtbildes möglich ist.Die - hermeneutisch durchaus erwünschten - Grenzen dieser Synthese liegen darin, daß nun auch in qualitativer Hinsicht so viele Daten bereitliegen, daß ein Interpret Mühe haben wird, daraus ein kommunikativ schlüssiges Gesamtbild des Textes und damit der Intentionen des Autors zu verfassen. Es zeichnet sich damit die Möglichkeit ab, daß verschiedene Forscher sich relativ leicht tun werden, bei den einzelnen Textanalysen zu gleichen Befunden zu kommen, daß sie aber dann divergieren, wenn es darum geht, aus der Fülle der Befunde ein kommunikatives Gesamtbild des Textes zu formulieren. Ein simples Beispiel besteht darin, daß der eine Forscher den Text letztlich in seinem Wortsinn akzeptiert, der andere aber meint, dieser Wortsinn, über den er mit dem Kollegen noch einig ist, sei insgesamt ironisch zu verstehen, also gegenteilig. Grammatisch faßbare Indizien für Ironie gibt es normalerweise nicht. Vielleicht meint aber der zweite Forscher aufgrund seines kommunikativen Wissens, er könne die gebotene Inhaltskonstruktion mit Recht im ironischen Sinn interpretieren.