

Kaum ein Medium ist in unserer Zeit so stark in den Mittelpunkt des öffentlichen Interesses getreten wie das Internet, präziser: das WWW als der benutzerfreundlichste Dienst im Internet. Und kaum ein Medium ist selbst in einem so starken Wandel begriffen - was unmittelbar mit der unerwartet hohen und schnellen Akzeptanz desselben zusammenhängt. Mit der allgemeinen Verfügbarkeit von mehr Information, als das menschliche Gehirn sich vorzustellen vermag, wächst die Notwendigkeit, immer gezielter auf bestimmte Information zugreifen zu können. Suchdienste und Suchmaschinen sind damit die wichtigsten täglichen Helfer bei der Recherche im WWW geworden. Dass es dieser Suchmaschinen bedarf, liegt an einem Grundprinzip des Aufbaus des Internet: Der Nutzer kann mit Hilfe seines Browser das WWW nicht(!) durchsuchen, sondern zunächst lediglich konkrete Inhalte (nämlich HTML-Seiten (1)) anfordern. Dies geschieht über das direkte Eintragen der Adresse eines Dokuments in der Adressleiste des Browsers:
Abb. 1: die Adressleiste im Browser
oder das Anklicken eines Hyperlinks, was seinerseits browserintern wieder einen Adressaufruf auslöst. Um die gewünschte Information zu finden, muss also entweder die genaue Lokation der Seite (URL, Uniform Resource Locator. Adresse für ein bestimmtes Dokument im World Wide Web) bekannt sein, oder man folgt den von einer anderen Person vorgedachten Verweisen in der Hoffnung, dass diese zum gewünschten Rechercheergebnis führen.
Einen grundlegend anderen Zugang zu den Inhalten bieten die Suchmaschinen, die es dem Benutzer ermöglichen, viele Seiten gleichzeitig nach bestimmten Begriffen zu durchsuchen.
Gibt der Anwender einen Suchbegriff ein, fordert er nicht etwa eine bestehende Seite an - auch wenn ihm dies suggeriert wird - sondern er sendet vielmehr den Befehl über das Internet, eine Suchmaschine zu starten. Das Ergebnis der Suche wird dem Benutzer wiederum in Form einer HTML-Seite präsentiert. Diese Seite liegt also nicht bereits auf dem Server vor, um abgerufen zu werden, sondern wird vielmehr als Ergebnis der Suchmaschine individuell generiert. Wir sprechen dabei von "dynamisch generiertem HTML" oder der Generierung "on the fly".
Voraussetzung für den Einsatz dieser Technologie ist, dass der Webclient (=der Browser) mit dem Webserver stärker in Interaktion treten kann, als nur Adressen aufzurufen: es müssen nunmehr Daten vom Client an den Server übertragen werden. Die Übertragung dieser Daten geschieht nach einem definierten Codierungsschema bzw. präziser Kommunikationsprotokoll, dem sogenannten CGI (Common Gateway Interface).
Ein spezielles Programm, ein sog. CGI-Skript, ermöglicht es dem Server, die auf diesem Wege eingehenden Daten beliebig weiterzuverarbeiten, also z.B. auch, eine Suchanfrage an eine auf dem Server hinterlegte Datenbank zu starten und das Ergebnis in HTML darzustellen. CGI-Skripts können in den unterschiedlichsten Programmiersprachen erstellt sein. Die gebräuchlichsten sind PERL und C++ bzw. für die Macintosh-Welt AppleScript.
Seit es eine CGI-fähige TUSTEP-Version gibt, ist die gesamte Leistungsfähigkeit dieses Programms mit all seinen Möglichkeiten, Texte zu durchsuchen, zu analysieren und zu präsentieren, auch für die Recherche in WWW-basierten Datenbanken verfügbar.
Neben der Leistungsfähigkeit und Geschwindigkeit ist ein entscheidendes Argument für den Einsatz von TUSTEP als CGI-Skript-Sprache, dass die vorhandenen TUSTEP-Dateien unverändert als Grundlage für die Recherche herangezogen werden können. Die einzige Bedingung ist das Einhalten einer (frei definierbaren) wiederkehrenden Struktur, die es dem Programm ermöglicht, einzelne Datensätze voneinander zu unterscheiden. Damit wird es möglich, selbst Satzdaten unverändert auf einen Webserver zu legen und über ein CGI-Skript durchsuchbar zu machen.
Das Wesen des Cross Media Publishing ist es, aus einem Datenbestand unterschiedliche Publikationen mit möglichst hohem Automatisierungsgrad erstellen zu können. Diese Bedingung wird durch den Einsatz von TUSTEP in nahezu idealer Weise erfüllt. Denn mit dieser Software kommt nur noch eine Arbeitsumgebung für die Erarbeitung, Korrektur, Formatierung und Ausgabe im Printmedium und für die Publikation im Internet zum Einsatz.
Hinzu kommt, daß mit diesem Werkzeug (das sich auch für die Publikation in Printmedien schon immer auf sachlich orientierte und an den inhaltlichen Bedürfnissen der einzelnen Projekte ausgerichtete Markierungen gestützt hat) auf Daten zugegriffen werden kann, deren Struktur - neben in XML
(2)
- in fast beliebiger Syntax markiert ist. Das dürfte zahlreichen Projekten, die bereits seit vielen Jahren mit eigenen Auszeichnungsschemata arbeiten, den Einstieg in die Welt des Internet deutlich erleichtern, da hierfür keine umfangreichen Konvertierungen notwendig sind.
Ähnlich stellte sich die Situation beim ROCHE-Lexikon Medizin
(3)
dar. Die zur Verfügung stehenden Quelldaten (Satzdaten und die Quelldaten der CD-ROM) hatten proprietäre Strukturen.
In einem ersten Schritt wurden diese vereinheitlicht, sodass die TUSTEP-basierte Suchmaschine die einzelnen Datensätze erkennen kann. Die TUSTEP-interne Satznummer dient dabei als hinreichende Datensatz-Identifikationsnummer, über die später der Zugriff auf die einzelnen Daten erfolgt. Nach Vereinheitlichung der Daten wurden - wiederum mit den TUSTEP-Mitteln - Indices erzeugt, die den Datenbestand erschließen und als Referenz ebenfalls die ID-Nummer enthalten. Nur diese Indices werden vom CGI-Skript durchsucht; das Ergebnis der Suche (die ID-Nummer) wird einem zweiten Programmteil übergeben. Dieser greift auf den Datensatz mit der gefundenen Nummer zu, um die Daten über eine x-table (Austauschtabelle) in gültiges HTML zu verwandeln und den so erzeugten Code der Webserversoftware (eingesetzt wird der Apache
(4)
HTTP Web Server) zu übergeben. Nach diesem Grundprinzip sind über 100.000 Stichwörter in Antwortzeiten von unter einer Sekunde durchsuchbar.
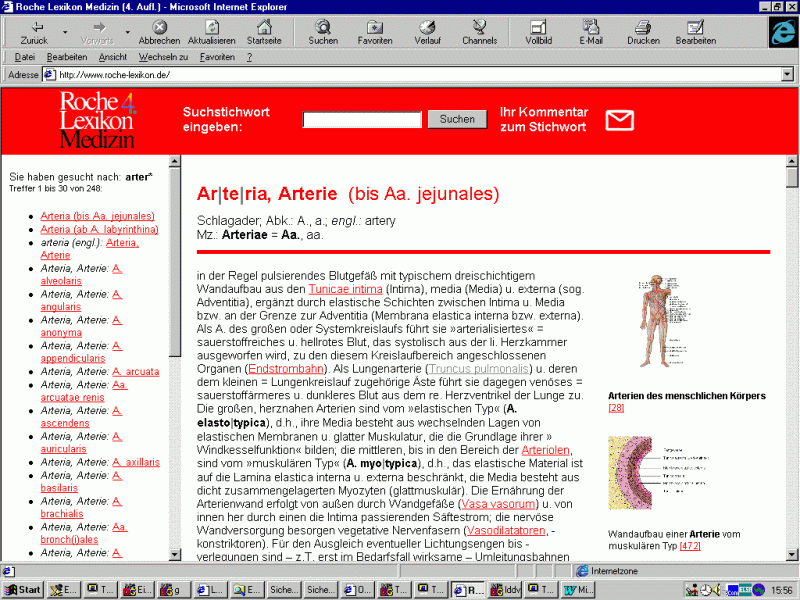
Führt eine Anfrage zu mehr als einem Treffer, wird zunächst eine Trefferliste (in Portionen zu 30 Treffern) generiert, aus der der Benutzer das gewünschte Stichwort auswählen kann. Parallel zu der Trefferliste wird das erste Stichwort der Liste angezeigt.
Abb. 2: der Aufbau von Roche online. Der linke frame beinhaltet die Trefferliste, rechts wird das erste Stichwort (Arteria) angezeigt. Im oberen frame ist die Suchmaske zu sehen.
Führt die Suchanfrage zu keinem Treffer, wird automatisch eine unscharfe Suche gestartet (hierfür wurde die Software SmartSpell der Firma Art Systems Research eingebunden, die eine speziell auf die medizinische Terminologie abgestimmte unscharfe Suche anbietet). Erst wenn auch diese keinen Treffer erzeugt, wird dem Benutzer eine entsprechende Meldung generiert.
Abb. 3: Ergebnis der Suche nach "Nuckofitzi"
Links-, Rechts- und Mittetrunkierungen sind ebenfalls möglich: So wird z.B. die Anfrage nach *itis alle Artikel auswerfen, in denen Entzündungen behandelt werden. Da sowohl der deutsche Stichworttext wie auch die englische Übersetzung durchsucht werden können, ist das ROCHE-Onlinelexikon gleichzeitig ein deutsch-englisches medizinisches Fachwörterbuch.
Die im gedruckten Lexikon enthaltenen Abbildungen werden automatisch als Thumbnails (kleine Bildvorschauen) in die dynamisch generierten HTML-Seiten eingebunden. Ein Mausklick auf ein solches Thumbnail bringt die betreffende Abbildung in voller Größe auf den Bildschirm..
Neben der Aufbereitung der Abbildungen waren es vor allem die Tabellen, die Handarbeit nach sich zogen. Der Code war nicht geeignet, um automatisch via Konvertierung nach HTML überführt zu werden (geschweige denn on the fly), zumal die Tabellen ihrerseits wieder z.B. Abbildungen enthalten, vor allem aber mit einer Fülle von harten Formatierungen auf die Erfordernisse des Buchformats getrimmt waren. Aus inhaltlichen wie pragmatischen Gründen wurden daher die Tabellen von einem Mediziner von Hand direkt in HTML codiert und der entsprechende Code in den dynamischen Seitenaufbau eingebunden (vgl. Abb. 4).
Abb. 4: Eingebundene HTML-Tabellen
Die Formatierungen der HTML-Seiten erfolgen vollständig über StyleSheets. Das ermöglicht es dem auftraggebenden Urban & Fischer Verlag, die Anmutung der Seiten zu verändern, ohne über Kenntnisse der CGI-Programmierung verfügen zu müssen. Mehr noch: Da es möglich ist, bei unterschiedlichen Aufrufen unterschiedliche StyleSheets einzubinden, lassen sich die selben Daten im Netz in völlig unterschiedlicher Darstellung präsentieren - wichtige Voraussetzung für die Vergabe von Nutzungslizenzen an andere Online-Dienste.
Das gesamte Projekt wurde im Sommer 1999 in einem Zeitraum von ca. drei Monaten realisiert, von den ersten konzeptionellen Sitzungen bis zur Installation auf dem Webserver und Freigabe im Netz. Mit dem Start des Online-Portals XIPOLIS
(5)
der Holtzbrinck-Verlagsgruppe und der Bibliographisches Institut & Brockhaus AG im Frühjahr 2000 ist das Roche-Lexikon als frei recherchierbares Lexikon auch über eine der wichtigen Einstiegsseiten ins Internet verfügbar.
Anmerkungen:
(1)
HTML, die HyperText Markup Language, ist die Sprache, in der üblicherweise die websites abgefasst sind. Sie beschreibt mit ca. 60 unterschiedlichen Auszeichnungsmöglichkeiten die logischen und z.T. typographischen Bestandteile eines Dokuments
(2)
XML, die "Extensible Markup Language", ist inzwischen als Standard für anwendungs- und medienneutrale, inhaltlich orientierte Textauszeichnung etabliert. Seine (erfreulich rasche) Verbreitung hat in vielen Projekten erstmals die Notwendigkeit medien- und andwendungsneutraler Datenhaltung überhaupt ins Bewußtsein gebracht.
(3)
Roche Lexikon Medizin. Hrsg. von der Hoffmann-La Roche AG. 4., neubearb. u. erw. Aufl., München: Urban & Fischer 1999
(4)
http://www.apache.org
(5)
(http://www.xipolis.net)
aus:
Protokoll des 77. Kolloquiums
über die Anwendung
der EDV in den Geisteswissenschaften am 27. November 1999


(zurück)
(zurück)
(zurück)
(zurück)
(zurück)