

Seit Oktober 2002 erscheint nun die Kölner Ausgabe (KA) der Werke Heinrich Bölls im Verlag Kiepenheuer & Witsch. Diese Ausgabe beruht auf den zu Lebzeiten Bölls veröffentlichten Texten sowie auf den Nachlässen, die in den Archiven der Erbengemeinschaft Heinrich Böll und der Stadt Köln aufbewahrt werden. Es handelt sich um ein 27 Bände umfassendes Großprojekt, das bedeutendste, das der traditionsreiche Verlag des Literatur-Nobelpreisträgers Heinrich Böll bislang zu verantworten hatte. Es ist auf einen Publikationsrhythmus von drei Bänden pro Jahr angelegt, also insgesamt auf einen Zeitraum von knapp zehn Jahren.
Die KA bietet das Werk Heinrich Bölls in gattungsübergreifender, der Chronologie der Veröffentlichung folgender Anordnung. Aus dem Nachlass edierte Texte werden entsprechend ihrer Entstehungszeit aufgenommen. Dies gilt auch für die zu Lebzeiten des Autors erschienenen Texte aus dem Frühwerk bzw. posthum publizierte Arbeiten. Die Interviews und Gespräche Heinrich Bölls werden im Rahmen der KA in gesonderten Bänden dokumentiert. Sämtliche in die Ausgabe aufgenommene Texte werden in textkritisch durchgesehener Form geboten. Textgrundlage sind die Erstdrucke oder die wirksam gewordenen Drucke der autorisierten bzw. der Werkausgabe von 1977. Orthographie und Interpunktion der Textgrundlage werden, unter Bewahrung charakteristischer Schreibeigenheiten Bölls, den zum Zeitpunkt der Entstehung bzw. Veröffentlichung geltenden Regeln angeglichen.
Alle Bände enthalten einen editorischen Anhang mit Informationen zur Textentstehung und - falls erforderlich - zum zeitgeschichtlichen und biographischen Hintergrund. Bei den größeren Erzähltexten wird deren zeitgenössische Aufnahme durch eine Auswahl repräsentativer Rezensionen dokumentiert. Bei der Darstellung der Textentstehung bezieht die Ausgabe vorangehende Arbeitsstufen ein. Sie bietet im Rahmen der Textgeschichte und stellenbezogener Erläuterungen charakteristische Umformungen der dem Druck vorausgehenden Niederschriften. Darüber hinaus enthält der Apparat Hinweise zur Textkonstitution, eine Verzeichnung der Überlieferungsträger sowie des Erstdrucks und der wirksam gewordenen weiteren Drucke. Der Stellenkommentar vermittelt zeitgeschichtliche Verweise in Form von Sacherläuterungen. Den Einzelbänden ist jeweils ein Register mit allgemeinen Angaben zu den genannten Personen sowie ein Register aller im Band erwähnten Texte Bölls beigegeben. Zum Abschluss der Edition erscheint ein kommentiertes Gesamtregister.
Es versteht sich, dass ein solches Projekt ein komplexes Zusammenspiel der unterschiedlichsten Personen und Institutionen, Kompetenzen und Kooperationsformen, Entscheidungsebenen und Vertragsregelungen erfordert. Beteiligt sind zum einen die Rechteinhaber, d.h. die Erbengemeinschaft Heinrich Böll, vertreten durch René Böll, zum anderen der Verlag, schließlich der Kreis der Herausgeber: érpéd Bernath (Universität Szeged/Ungarn), Hans Joachim Bernhard (Universität Rostock), Robert C. Conard (Universität Dayton, Ohio/USA), Frank J. Finlay (Universität Leeds/Großbritannien), James H. Reid (Universität Nottingham/Großbritannien), Ralf Schnell (Universität Siegen), Jochen Schubert (Heinrich-Böll-Archiv Köln). Für die Förderung des Projekts konnten gewonnen werden: die StadtBibliothek Köln, das Heinrich-Böll-Archiv, die Heinrich Böll Stiftung Berlin, die Universität Siegen, der Beauftragte der Bundesregierung für Angelegenheiten der Kultur und Medien, das Ministerium für Schule, Wissenschaft und Forschung des Landes Nordrhein-Westfalen, die Stiftung Kunst und Kultur des Landes Nordrhein-Westfalen und die Stadtsparkasse Köln.
Um dieses Projekt editionstechnologisch zu sichern, war es notwendig, eine Editionssoftware zu entwickeln, die den spezifischen Anforderungen dieser Ausgabe gerecht wird. Im folgenden wird das Profil dieser Editionssoftware im einzelnen dargestellt.
Für Bearbeiter sollen normale Textverarbeitungskenntnisse ausreichen, um mit dem System arbeiten zu können. Insbesondere sollen keine Kenntnisse über die technische Realisierung für den Einsatz der Software notwendig sein. Es soll durch die Software sichergestellt werden, dass nicht mehrere Bearbeiter einen Text zur gleichen Zeit bearbeiteten können, was wahrscheinlich zu Inkonsistenzen der Daten führen würde. Alle Bearbeiter sollen zwar alle Texte lesen, allerdings nur die ihnen zugeteilten Texte bearbeiten können. Die Texte sollen den Bearbeitern zentral zu Verfügung gestellt werden, wobei Zwischenstände oder abgeschlossene Texte für alle Bearbeiter zur Verfügung stehen müssen. Gleichzeitig soll damit eine Sicherung der bisherigen Arbeit erfolgen.
Der Satz soll vollautomatisch laufen. Dadurch gewonnene zusätzliche Informationen, wie z.B. Seitenumbrüche und Trennungen, sollen in die Dokumente wieder einfließen, um eine elektronische Zitierfähigkeit der Texte zu erhalten.
Die für die Texterfassung grundlegende DTD wurde von der Firma OKA anhand des Leitfadens "Einem Autor folgen" [Heinrich Böll Stiftung e.V. Berlin in Zusammenarbeit mit der Erbengemeinschaft Heinrich Böll, der StadtBibliothek Köln und dem Heinrich-Böll-Archiv (Hrsg.), Köln: Verlag Kiepenheuer und Witsch. 1998] entworfen. Die DTD folgt dabei nicht notwendig dem typographischen Aufbau eines Textes, sondern gliedert und ordnet die Textelemente gemäß ihrer Semantik unter hierarchischen Gesichtspunkten. Mit Beginn der editorischen Arbeiten an den Texten wurde die DTD in einem kontinuierlichen Prozess den Gegebenheiten angepasst. Dabei war es bisher nicht notwendig, bereits erfasste Dokumente nachzubearbeiten.
Im Gesamtbestand kann ein Dokument über die in ihm enthaltene ID eindeutig identifiziert werden. Alle relevanten editorischen Textelemente erhalten eine für das Dokument eindeutige ID. Somit sind diese Elemente durch die Kombination von Dokument- und Element-ID im Gesamtbestand eindeutig gekennzeichnet. Dies wird vor allem für dokumentinterne und dokumentübergreifende Verweise verwendet. Während der editorischen Arbeit an den Texten können die Bearbeiter mit Hilfe dieser Verweise Textstellen direkt referenzieren. Im Satz werden die Verweise dann durch die konkreten Seiten- und Zeilenzahlen ersetzt. Pro Band existiert neben den zugehörigen Texten jeweils eine zusätzliche Datei für Bibliographie und Register. Die Bibliographie wird wie ein normales Dokument bearbeitet, während dem Register eine eigene DTD zugrunde liegt. Aufgrund der komplexen Struktur des Registers kann dieses nur über spezielle Erweiterungen bearbeitet werden. Um den Entwicklungsaufwand zu reduzieren und auf die spezifischen Anforderungen zu konzentrieren, wurde auf flexibel erweiterbare Standardsoftware zurückgegriffen.

Soll ein längerer Abschnitt kommentiert werden, so wird das Ende des Abschnittes markiert und der Kommentar erstellt. Anschließend wählt der Bearbeiter den Anfang des zu kommentierenden Bereiches und markiert aus dem erscheinenden Dialog die entsprechende Endpassage (Abbildung 2):
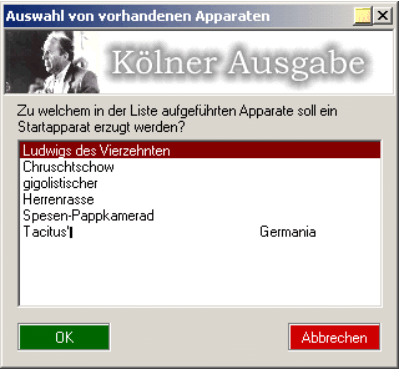
Dabei werden nur die in Frage kommenden Passagen aufgeführt, also zum Beispiel keine kommentierten Stellen, die vor dem markierten Bereich liegen.
Varianten arbeiten analog wie Stellenkommentare. Die Unterscheidung zwischen Stellenkommentaren und Varianten ist durch eine unterschiedliche Farbgebung gekennzeichnet. Existiert zu einer Textstelle sowohl ein Kommentar als auch eine Variante, so werden beide Textboxen untereinander im Text dargestellt.
Möchte der Bearbeiter sich zum Beispiel in einem Kommentar auf die Textstelle beziehen, so fügt er einen Verweis ein. Die Erweiterung bietet ihm dazu eine Liste mit den Kurzbeschreibungen der im Dokument existierenden Bezüge an. Aus dieser Liste wählt er den gewünschten Bezug, und die Erweiterung erstellt einen Verweis, der die interne ID des Bezuges verwendet.
Für Bezüge, die sich über einen Bereich erstrecken, legt man zuerst am Beginn des Bereiches einen Bezug an. Danach erzeugt man am Ende des Bereiches einen Endbezug, welcher aus einer Liste der in Frage kommenden Startbezügen ausgewählt wird.
Die Erweiterungen bieten dem Bearbeiter die Möglichkeit, von einem Bezug zu den zugehörigen Verweisen zu springen bzw. von den Verweisen zum Bezug.
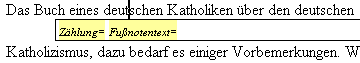
Bei den Fußnoten unterscheidet die Software zwischen dem Text, welcher von Böll stammt, und dem kommentierten Bereich. Im Bölltext muss die Nummerierung der Fußnote manuell geschehen, da diese nicht immer einem durchgängigen Schema folgt. Im Kommentarteil fällt die Eingabemöglichkeit für die Zählung weg, weil hier die Software eine automatische Nummerierung der Fußnoten vornehmen kann.
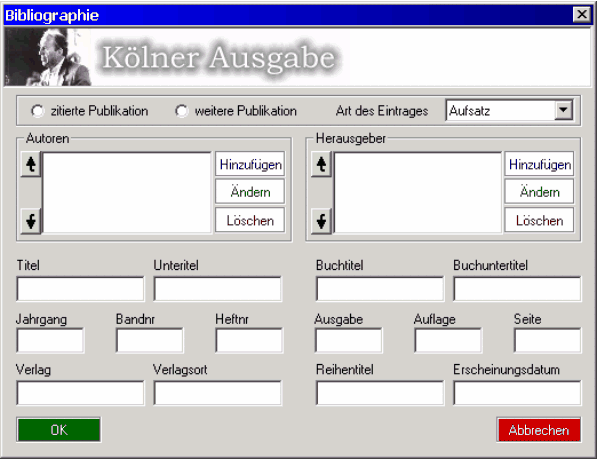
In dieser Maske kann der Bearbeiter die Autoren oder Herausgeber angeben. Dabei kann natürlich die Reihenfolge der Personen verändert werden. Alle Daten, abgesehen vom Titel, Publikationstyp und Art des Eintrags, sind optional und müssen nicht unbedingt angegeben werden. Die Bibliographie ist in zwei Bereiche eingeteilt. Zum einen gibt es die "zitierte Literatur", welche alle Publikationen beinhaltet, aus denen zitiert wurde. Außerdem gibt es den Bereich "weitere Publikationen", in den alle anderen Publikationen fallen. Beim Anlegen eines neuen Bibliographieeintrages muss einer der beiden Publikationstypen angegeben werden. Die "Art des Eintrags" gibt an, um was für eine Publikation es sich handelt. Dabei sind die Arten "Aufsatz", "Buch", "Sammelwerk", "Zeitschrift" und "Zeitung" möglich. Je nach Art des Eintrags ändern sich auch die möglichen Eingabefelder.
Die Darstellung der Einträge im Dokument entspricht weitestgehend der Typographie des Druckbildes. Zum Ändern oder Löschen von Einträgen kann sich der Bearbeiter über die Erweiterung eine Liste aller Einträge anzeigen lassen, womit er den Eintrag entweder löschen oder wieder in der Eingabemaske öffnen kann.
Das eigentliche Register wird in einem zusätzlichen XML-Dokument gespeichert, das der Registerbearbeiter erst mit Hilfe der Erweiterung "einchecken" muss. Dies bedeutet, dass er zunächst die Registerdatei vom Server laden muss. Danach "checkt" er das Dokument bei der Erweiterung ein. Erst dann kann mit dem Register gearbeitet werden. Nach Abschluss der Bearbeitung muss das Register "ausgecheckt" und auf den Server geladen werden. Dieses Verfahren stellt sicher, dass es immer nur eine Person gibt, welche am eigentlichen Register arbeitet.
Das Registerdokument selbst bekommt der Bearbeiter nicht zu sehen, sondern er arbeitet immer nur indirekt über die Erweiterung darauf. Ist für einen Band ein Registerdokument vorhanden, so wird jedes andere Dokument, welches zu diesem Band gehört, beim Öffnen nach Registervorschlägen durchsucht. Dabei wird ein Abgleich zwischen dem Register und dem Dokument gemacht. Sollte es Stellen geben, welche Registervorschläge haben und bisher noch nicht dem eigentlich Register bekannt sind, so werden diese Stellen unter dem Eintrag "Unzugeordnete Einträge" aufgelistet.
Der Registerbearbeiter kann nun im Register neue Einträge anlegen, zum Beispiel für eine Person. Um eine vorgeschlagene Textstelle einem Eintrag zuzuordnen, wählt der Bearbeiter einfach den Eintrag der unzugeordneten Textstelle aus und kann dann den Person-, Ort- oder Titeleintrag wählen, dem die Textstelle zugeordnet werden soll (Abbildung 5):
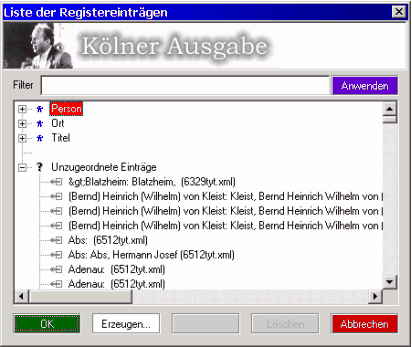
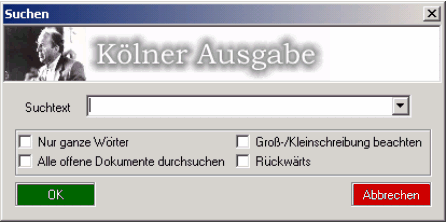
Dabei soll vor allem die Möglichkeit erwähnt werden, in allen zurzeit geöffneten Dokumenten zu suchen (XMetaL bietet, wie viele Editoren, die Funktionalität, mehrere Dokumente gleichzeitig offen zu haben und zwischen diesen hin und her zu schalten).
Des Weiteren wird eine Liste der bereits eingegebenen Suchwörter mitgeführt. Dies erspart dem Anwender die erneute Eingabe und somit Zeit und Schreibarbeit.
Die im XML-Editor vorhandene Kopier- und Einfügoperation vom ausgewählten Bereich kopiert außer dem eigentlichen Text auch die Markup-Informationen. Dies ist zwar nützlich, solange man sich in XMetal befindet, bereitet dem Anwender jedoch erhebliche Probleme, wenn dieser eine markierte Passage in anderen Programmen benutzen möchte. Daher bietet die Erweiterung auch die Möglichkeiten des Exports eines gewählten Bereiches als reiner Text. Dieser kann entweder als Datei gespeichert oder wieder in die Zwischenablage kopiert werden.
Die Erweiterung unterstützt den Anwender mit Hilfe des in Abbildung 7 gezeigten Dialogs:
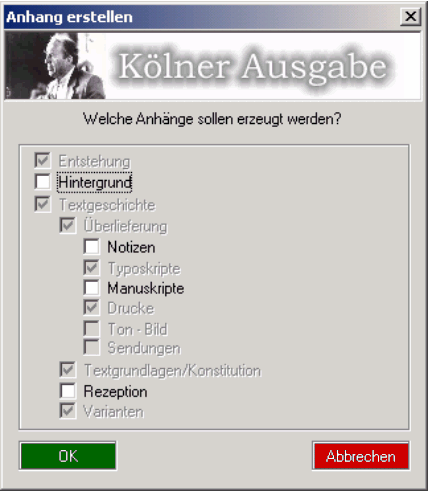
Vor dem Aufruf überprüft die Software, welche Anhangteile bereits im Dokument vorhanden sind und welche noch fehlen. Bereits vorhandene Teile werden in der Übersicht deaktiviert, da es nicht möglich ist, einen bereits hinzugefügten Anhang über diesen Weg wieder zu löschen. Die Gefahr einer unbeabsichtigten Löschung ist zu groß. Die noch nicht eingefügten Gliederungen können einfach ausgewählt werden. Die Erweiterung achtet dabei darauf, dass vorhandene Abhängigkeiten auch eingehalten werden. Somit ist es zum Beispiel nicht möglich, den Anhang "Drucke" ohne die Anhänge "Überlieferung" und "Textgeschichte" zu erzeugen.
Vor jedem Öffnen eines Dokumentes in XMetaL überprüft die Erweiterung, ob dieses sich noch in einem einwandfreien Zustand befindet (Abbildung 8):
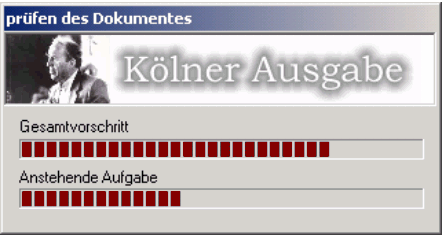
Dabei wird zum einen geprüft, ob die Struktur noch nach der vorhandenen DTD gültig ist. Des Weiteren wird geprüft, ob die vergebenen ID korrekt und/oder doppelt verwendet wurden (beispielsweise durch einen möglich Absturz von XMetaL). Weitere Prüfungen stellen sicher, dass mit dem Dokument gearbeitet werden kann. Falls sich herausstellen sollte, dass etwas mit dem Dokument nicht stimmt, wird der Benutzer darüber informiert und erhält die Anweisung, sich mit dem technischen Support in Verbindung zu setzen. Das weitere Arbeiten an diesem Text ist dann nicht möglich.
Der Satzgenerator erzeugt mittels TUSTEP aus einem XML-Dokument eine fertig gesetzte PostScriptdatei, die weitestgehend dem fertigen Satz entspricht. Verweise auf Bezüge werden vom Satzgenerator in konkrete Seiten und Zeilennummern umgewandelt und erscheinen als solche im gesetzten Text.
Die Bearbeiter können den Satzgenerator direkt aus XMetaL über die Erweiterung starten. Vor dem eigentlichen Start des Satzgenerators erscheint der in Abbildung 9 gezeigte Dialog:
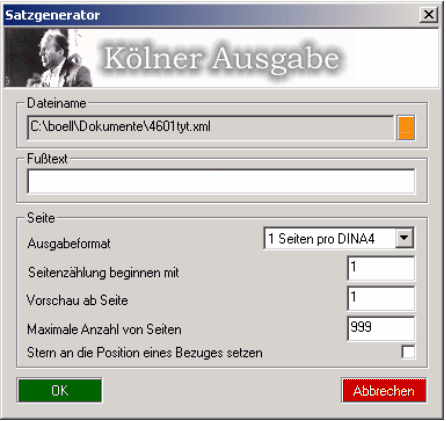
Hier können vorher noch verschiedene Einstellungen vorgenommen werden, welche hauptsächlich das Erscheinungsbild des Satzes bestimmen. Unter anderen kann das Ausgabeformat bestimmt werden. Der Anwender hat die Wahl zwischen "eine Seite pro DIN A4", "eine Seite pro DIN A4 gezogen" und "zwei Seiten pro DIN A4". Zudem existiert die nützliche Funktion, Bezüge mit einem Stern zu kennzeichnen, welche sonst nicht im Satz erscheinen würde.
Nach dem Durchlauf des Satzgenerators wird anschließend die erstellte PostScriptdatei mittels der Software Ghostview angezeigt. In der nächsten Version der Software wird mittels des Adobe Acrobat Writers aus der PostScriptdatei zunächst eine PDF-Datei erzeugt, die sich dann mit Hilfe des kostenlosen Acrobat Readers auf vielen verschiedenen Rechnerplattformen anzeigen läst.
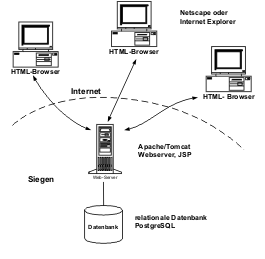
Der Server besteht aus der Webserversoftware Tomcat, welche für die dynamische Erzeugung der Webseiten zum Einsatz kommt. Weiterhin wird die Datenbank PostgreSQL für die Datenhaltung eingesetzt. Die Verbindung zwischen diesen beiden Softwares geschieht mittels Java-Servlets, die die Programmfunktionalität des Servers enthalten.
Jeder Benutzer des Servers muss sich zuerst mittels Benutzernamen und Passwort identifizieren und erhält dann anhand der ihm zugeteilten Rechte Zugang zu dem Server. Die Dokumente sind auf dem Server nach Bänden geordnet, und einem Bearbeiter können Lese- und Schreibrechte auf die einzeln Bände erteilt werden.
Bearbeiter laden die Texte vom Server herunter, um diese auf ihrem Rechner anschließend offline zu bearbeiten. Danach laden die Bearbeiter ihre Dokumente wieder auf den Server. Ein Text kann nur von einem Bearbeiter zur gleichen Zeit ausgeliehen sein (Abbildung 11):
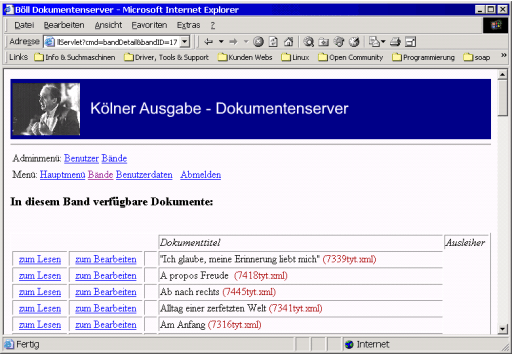
Damit wird verhindert, dass durch gleichzeitiges Bearbeiten desselben Textes Inkonsistenzen entstehen. Benötigt ein Bearbeiter einen Text nur zum Nachschlagen, so kann er jederzeit einen Text nur zum Lesen herunterladen. Dieser Text kann dann allerdings weder bearbeitet noch erneut auf den Server hochgeladen werden.
Der Server erstellt jedes Mal, wenn ein Bearbeiter einen Text wieder hochlädt, intern eine neue Version des Dokumentes. Nach außen ist immer nur die aktuelle Version sichtbar, es sind aber alle Versionen eines Dokumentes auf dem Server vorhanden. Löscht ein Bearbeiter z.B. einen Textteil und merkt dies erst nach dem Hochladen auf den Server, so kann man problemlos auf den vorherigen Stand des Dokumentes zurückgehen.
Wird ein Dokument wieder auf den Server hochgeladen, so wird nur die Version des Dokuments akzeptiert, die heruntergeladen wurde. Damit wird verhindert, dass ein Bearbeiter aus Versehen eine ältere Version eines Dokuments auf den Server lädt. Weiterhin führt der Server mehrere Überprüfungen der Dokumentstruktur durch, um zu verhindern, dass fehlerhafte Dokumente auf den Server geladen werden.
In der nächsten Version des Servers wird es den Bearbeitern möglich sein, online verschiedene Recherchen in dem Datenbestand durchzuführen. Zum einen wird eine Volltextsuche über alle Dokumente zu Verfügung stehen. Bei den Suchergebnissen wird zuerst nur ein Textabschnitt aus dem Dokument angezeigt, und auf Wunsch kann der Bearbeiter sich dann auch das ganze Dokument anzeigen lassen. Weiterhin stehen Recherchemöglichkeiten zum Auffinden von Kommentaren und zur Suche im Register zur Verfügung.
Aus diesem Grund wurde eine spezielle Installations-CD hergestellt, die alle Komponenten enthält. Installiert werden die benötigten Komponenten automatisch über ein spezielles Setupprogramm, das die Installationsprogramme der anderen Softwareprodukte ersetzt (Abbildung 12):
Der Bearbeiter kann in diesem Setupprogramm das Ziellaufwerk für die Software frei wählen, worauf automatisch die für sein System benötigten Komponenten installiert werden. Nach Abschluss der Installation stehen die Programme für den Bearbeiter fertig konfiguriert bereit.
Technische Unterstützung erfolgt über mehrere Mailinglisten, die speziell für dieses Projekt angelegt wurden, sowie über direkten Kontakt zu der Böll-Arbeitsstelle in Siegen.
Nach Abschluss der Arbeit stellen die Bearbeiter wieder alle Dokumente auf den Server, und die Firma pagina leiht sich die Dokumente für den ersten Probesatz aus. So wird sichergestellt, dass keine weiteren Arbeiten an den Dokumenten stattfinden, während diese sich im Satz befinden.
Stellt sich nach dem Korrekturlesen heraus, dass an Dokumenten noch Korrekturen notwendig sind, so werden diese Texte von der Firma pagina wieder auf den Server gestellt, damit der Bearbeiter sich das Dokument vom Server holen kann. Sind die Korrekturen ausgeführt, werden die Dokumente wieder auf den Server geladen, und die Firma pagina leiht sich diese wieder aus. Dieser Vorgang kann sich wiederholen, bis der endgültige Satz in Druck geht.
Auch schon fertig bearbeitete Dokumente bleiben auf dem Server verfügbar, um den Bearbeitern für Recherchen und als Grundlage für dokumentübergreifende Verweise zu dienen, die von einem Dokument eines noch zu bearbeitenden Bandes auf Textstellen in einem bereits fertig gestellten Band verweisen.
Das Projekt der "Kölner Ausgabe der Werke
Heinrich Bölls" steht im WWW unter:
http://www.heinrich-boell.de/stiftung/kaus.htm
aus: Protokoll des 85. Kolloquiums über die Anwendung der EDV in den Geisteswissenschaften am 29. Juni 2002