
Winfried Bader (Kath.-Theol. Seminar)
Ausdruckssyntaktische Untersuchung biblischer Texte
Summary
The author's approach of describing a text, which to a certain degree is dependent on MORRIS' theory of the functioning of signs, is divided into three distinct branches of inquiry: syntax, semantics, and pragmatics. Syntax, consequently, is concerned with the formal relations of signs to one another - a procedure being understood as an exclusively formal one completely abstracting from lexical meanings. In order to interpret a single text an index of its unlemmatized words must be arranged. Then, the data of this index can by means of TUSTEP computer programs be transformed into a graphic representation which is bound to be interpreted. As far as the example in Jud. 14:11-14.18.19* is concerned, the graphic representation of wordforms reveals two sections of the text which overlap at the end of verse 12 and at the beginning of verse 13. In respect of formal syntax this marks the text's culminating point that in this case exactly corresponds to the most important section of the text with regard to contents.Sprachwissenschaftlicher Hintergrund
Die ausdruckssyntaktische Untersuchung biblischer Texte ist ein Teilschritt eines Methodenvorschlags zur Textinterpretation, der sich am Zeichenmodell der Sprache orientiert. Nach Charles W. Morris (Grundlagen der Zeichentheorie, München 1972) hat ein Zeichen in seinem Verwendungsprozeß (Semiose) drei Dimensionen:- die syntaktische Dimension, das ist die Relation zwischen Zeichenträger und Zeichenträger,
- die semantische Dimension, das ist die Relation zwischen den Zeichenträgern und dem Designat,
- die pragmatische Dimension, das ist die Relation zwischen den Zeichen und ihren Interpreten.
Vor Beginn der Textinterpretation wird der Untersuchungsgegenstand Text festgelegt: Abgrenzung des Textes, Arbeitsübersetzung, Einteilung des Textes in Äußerungseinheiten, das sind Sätze oder auch Nicht-Sätze mit eigener kommunikativer Funktion (sie sind der Bezug für die gesamte weitere Interpretation), ggf. noch Text- und Literarkritik. Die Literarkritik führte bei vorliegendem Beispieltext Ri 14,11-19 zur Ausscheidung von vv15-17.19a-d.
Der erste Schritt der Interpretation ist die Ausdruckssyntax: Die Zeichenformen bzw. die Ausdrücke werden in ihrem Zueinander und Gegeneinander und in ihrer Verteilung im Text beschrieben. Dabei wird vom Inhalt dieser Ausdrücke vollkommen abgesehen und nur ihre phonetische oder graphische Gestalt beobachtet.
Der semantischen Dimension entspricht die Untersuchung der wörtlichen Bedeutung jeder einzelnen Äußerungseinheit. Sie wird metasprachlich genau beschrieben und interpretiert.
In der Pragmatik betrachtet die Textinterpretation die Äußerungseinheiten in ihrem Zusammenhang, ihre Funktion im Kontext; die wörtliche Bedeutung wird in die gemeinte Bedeutung überführt.
Die Ergebnisse der einzelnen Schritte werden zusammengeführt und gemeinsam interpretiert. Textübergreifende und außerliterarische Untersuchungen bringen die Interpretation zu ihrem vorläufigen Abschluß.
Ausdruckssyntax
Bei der Ausdruckssyntax gibt es zwei Fragerichtungen:- Die ausdruckssyntaktische Analyse des Gesamtkorpus einer Sprache: die Bauform der Wörter, ihre Bildungselemente, ihre Kombinierbarkeit und Zusammenordnung im Satz, d.h. die Erarbeitung einer oberflächenorientierten Morphologie unter Verzicht auf inhaltliche Kriterien.
- Die ausdruckssyntaktische Interpretation eines einzelnen Textes: Ein Text vermittelt seine Botschaft ausschließlich mit Hilfe seiner Ausdrücke. Aber auch die Ausdrücke selbst sind ein, vielleicht auch unbewußter, Aspekt des Gesamtinhalts. Reime, Assonanzen, Leitwörter lösen beim Hörer bestimmte Effekte aus. Es hieße, die Geschichtlichkeit der Welt zu leugnen, würde man diese "Materie" des Textes bei der Interpretation vernachlässigen. Die Ausdrücke weisen mehr als die Ideen und inhaltliche Aussagen zurück zur Entstehungssituation des Textes, zur Gemeinschaft der Menschen, die sich dieser Sprache bedienten. Die theologische Rede von Gottes Wort im Menschen Wort ist zunächst konkret auf die Ausdrucksseite des menschlichen Wortes zu beziehen.
Ausdruckssyntaktische Interpretation von Ri 14,11-19*
Der folgenden Interpretation liegt der Text Ri 14,11-14.18.19e zugrunde (19e: wa = yi[n]ten ...). Der Text wurde in Äußerungseinheiten eingeteilt, die zur genauen Bezugnahme je Vers mit Kleinbuchstaben durchgezählt sind. Es sind meist Verbalsätze (ein Satz hat nur ein finites Verb). Ausnahme: in v18 zwei Nominalsätze (c: ma(h) ... d: u(w) = mä(h) ...). Diese Einteilung in Äußerungseinheiten bildet den Bezug der weiteren Interpretation.Ausdruckssyntaktisch untersucht wird der hebräische Konsonantenbestand, eine Vorentscheidung, die hauptsächlich die graphische Form der Zeichen im Blick hat. Es interessiert die Frage, an welchen Stellen im Text gleiche Ausdrücke auftauchen. "Ausdruck" können dabei verschiedene Größen sein: Man kann bereits das Vorkommen der einzelnen Buchstaben untersuchen. Weiter können vorgegebene Kombinationen von Buchstaben (Silben, Zeichenfolgen) untersucht werden. Schwierig ist dann nur, nach welchen Kriterien man die Suchzeichenfolge bestimmt. Besser ist, zunächst mit festen Größen zu arbeiten und die Ausdrücke des Textes vollständig zu erfassen, d.h. man vergleicht alle Ausdrücke vorgegebener Größe. Setzt man noch keine oberflächenorientierte Bestimmung von Morphemen voraus, so ist die nächstliegende ausdruckssyntaktische Größe zur Untersuchung das graphische Wort, d.h. eine Folge von Buchstaben zwischen zwei unmittelbar aufeinanderfolgenden Blanks, Zeilenwechsel oder Maqqef. Jedes dieser Wörter des Textes wird nun geprüft, an welchen Stellen des Textes es genau in derselben Form belegt ist. Das ist die Frage nach einem vollständigen unlemmatisierten Wortregister. Seine Daten sind die Grundlage der ausdruckssyntaktischen Interpretation. Dafür werden die Daten umgesetzt in eine Graphik, "Distributionstabelle" genannt (vgl. Abb. 1):
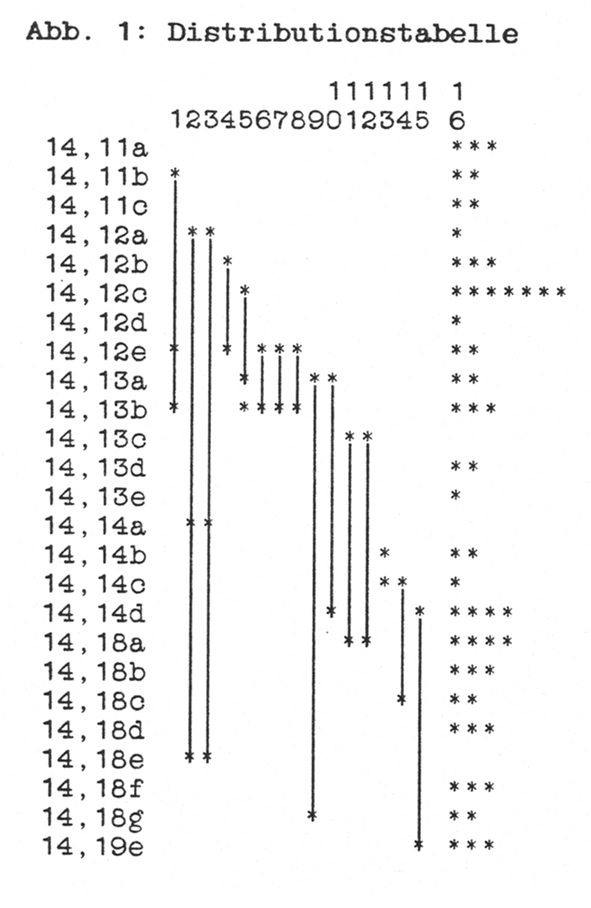
In der Distributionstabelle steht jeder Stern für ein Wort. Die Spalte gibt den Registereintrag an, zu dem es gehört, die Zeile die Referenz. Z.B. Spalte 1: Das Wort unter dem Registereintrag mit der laufenden Nummer 1 ist im Text dreimal belegt an den Stellen 11b, 12e, 13b. Obwohl für die inhaltsfreie Interpretation eigentlich uninteressant, findet sich in der Code-Tabelle (vgl. Abb. 2) zu jeder Spalte der Wortlaut des entsprechenden Registereintrags, z.B. Spalte 1 vertritt das Wort šlšym (slsym). Die Linien sollen graphisch die Zusammengehörigkeit einer Spalte und ihren ersten und letzten Beleg unterstützen. Spalte 16 hat einen Sonderstatus: Hier sind aus Gründen des Tabellenformats alle Wörter zusammengefaßt, die im Text nur einmal belegt sind.

Betrachtet man die Tabelle zu Ri 14,11-19*, so fallen zwei Teile auf. Ein Anfang 11a-13b, oder besser Spalte 1-8, und ein Schluß 13a-19e, oder besser Spalte 9-15. Im Bereich 12e-13b greifen beide Teile ineinander, hier liegt der ausdruckssyntaktische Akzent des Texts. Der eigentliche Textanfang 11a-12d ohne Wiederholungen (Spalte 1-5) kommt mit drei Wörtern in 12e-13b zum Abschluß. Die Spalten 2-3 gewährleisten die Kontinuität. 12e setzt mit den ersten Wiederholungen und seiner Länge einen deutlichen Akzent, den 13b durch den Rückgriff auf 12e aufnimmt. Beide Äußerungseinheiten sind im Zentrum des Textes eng aufeinander bezogen. Interessant ist, daß die zwei Äußerungseinheiten nicht aus dem Text herausfallen, sondern zum einen den ersten Teil abschließen, zum andern den Anfang des zweiten Teils (13a) umschließen. Der zweite Teil zeichnet sich dadurch aus, daß er durch die beiden alternierend belegten Wortpaare strukturiert ist. Die Wortschatzzunahme geht weiter, die Wiederholungen lassen keine besonderen Akzente erkennen. Durch die alternierenden Wortpaare weist der 2. Teil in seiner Gliederung auch über sich hinaus, zurück auf den ersten Teil. Denn das Wortpaar begegnet erstmals in 12a, das Gliederungsprinzip beginnt also bereits dort. Damit ist über die Akzentstelle hinweg der Text durchkomponiert.
Von der ausdruckssyntaktischen Interpretation zurück zum Inhalt: Der Textanfang stellt die Personen und die Situation vor. Simson beginnt seine Rede und schlägt eine Wette vor. In 12e wird der Gegenstand der Wette genannt. Betont wird die Beziehung dieser Abmachung mit den Angeredeten: šlšym (slsym) und lkm werden wiederholt. 13a ist gedanklich ein Vorgriff auf die weitere Erzählung, Wörter aus dieser Äußerungseinheit werden im weiteren Text aufgenommen. 13b bringt die Wette und die Rede Simsons zum Abschluß. Inhaltlich ist es eine genaue Entsprechung zu 12e. Die ausdrucksformale Akzentstelle des Textes ist in dem vorliegenden Text gleichzeitig auch der inhaltliche Knackpunkt: Es geht um die Wettabmachung.
Die gliedernden Elemente des zweiten Teils 14a.18e bzw. 13c.18a sind Redeeinleitung. Der zweite Teil des Textes gliedert sich bis auf 14d und 19e in Rede und Gegenrede. Und durch eine Rede eingeleitet in 12a sind die beiden Teile auch zusammengebunden.
Das TUSTEP-Programm
Die Erhebung des Befundes und die Ausgabe der Graphik wurden mit TUSTEP durchgeführt. Dabei wurde die Eigenschaft von TUSTEP ausgenützt, daß sich die einzelnen Programmbausteine zur Lösung von Standardproblemen sehr differenziert verändern lassen und daß die Übergabe zwischen den Programmbausteinen immer in Textdateien erfolgt, die mit jedem anderen Baustein weiterverarbeitet werden können. Durch Kombination der Bausteine lassen sich eigene Problemlösungen erarbeiten.Ausgangspunkt des Programms ist ein Text, Endpunkt ist die graphische Darstellung der Distributionstabelle.
Im ersten Schritt wird der Text für die Eingabe ins Hauptprogramm vorbereitet (TUSTEP-Programm: KOPIERE). Bei diesem vorbereitenden Schritt kann der Wissenschaftler noch seine Wünsche und sein Sprachverstehen einbringen. Danach läuft das Programm für alle Texte gleich ab. Zunächst wird ein Wortregisters erstellt, dessen Referenzen formal eindeutig gestaltet sind (TUSTEP-Programme: REGISTER-VORBEREITE, SORTIERE, REGISTER-AUFBEREITE). Die Daten des Registers müssen dann in Koordinaten für Spalte und Zeile umgesetzt werden. Die Zeile ist direkt durch die Referenz gegeben, die Spalte ist die laufende Nummer des Registereintrags in der Reihenfolge des Textes. Dafür werden die Registereinträge wieder in die Textreihenfolge gebracht, indem man sie nach ihrer ersten Referenz sortiert (TUSTEP-Programme: SORTIER-VORBEREITE, SORTIERE). Damit kann man den Registereinträgen eine laufende Nummer (= Spaltennummer) zuordnen und gleichzeitig die Einzelwörter gesondert kennzeichnen (TUSTEP-Programm: KOPIERE). Ausgegeben werden die Zahlenpaare sowie die Code-Tabelle, welche den Registereintrag mit der entsprechenden laufenden Nummer identifiziert.
Die Zahlenpaare in Form von TUSTEP-Korrekturanweisungen werden nun nach Spalten sortiert (TUSTEP-Programme: SORTIER-VORBEREITE, SORTIERE), um über Schleifenzähler die Korrekturanweisungen für die Striche zwischen den Sternen einer Spalte zu ergänzen (TUSTEP-Programm: KOPIERE).
Wenn die Korrekturanweisungen in die richtige Reihenfolge gebracht sind (TUSTEP-Programme: SORTIER-VORBEREITE, SORTIERE nach den Zeilennummern), können sie von KORREKTUR-AUSFUEHRE verwendet werden. Korrigiert wird eine leere Tabelle, die aus den Bezeichnungen der Äußerungseinheiten der Quelldaten erzeugt wurde (TUSTEP-Programm: KOPIERE). Hinter diesen Bezeichnungen ist jede mögliche Stelle für einen Stern durch ein festes Blank markiert. Bei der Korrektur werden die entsprechenden festen Blanks durch einen Stern bzw. einen Strich ersetzt. Diese Tabelle kann nun wie jede Textdatei ausgedruckt werden (TUSTEP-Programm: FORMATIERE, DRUCKE).
(Die Kurzfassungen der Referate wurden von den Referenten zur Verfügung gestellt.)
Zur Übersicht über die bisherigen Kolloquien