Damit verlangt schon der konventionelle Zugriff zu diesem Nachschlagewerk über das Ordnungsstichwort/Lemma Kenntnisse des Mittelhochdeutschen, eine Umordnung oder Filterung nach anderen Gesichtspunkten (Regionen, historisch, fachsprachlich usw.) für weitere wissenschaftliche Arbeiten erfordert zeitaufwendiges Duplizieren des Kataloges.
Der Hauptkatalog, wie diese Belegsammlung von uns genannt wird, umfaßt ungefähr 3,6 Mill. Belege, überwiegend handgeschriebene Unikate, die auch umfassende Beiträge zu Brauchtum, Aberglaube und Sachkunde der altösterreichischen Dialektlandschaften geben. Die Verteilung der Herkunft der Sammelbelege wurde vom Redaktor für diese Neukonzeptionsdiskussion ungefähr folgendermaßen eingeschätzt: 55% indirekt erhobene Fragebogenantworten bzw. freie Sammlungen, 35% direkt erhobene Mundartbelege, 10% Exzerpte aus (systematischen) Mundartsammlungen, Regionalwörterbüchern, Mundartliteratur und Dissertationen.
Dies zeigt deutlich, daß mehr als die Hälfte der Belege zwar systematisch abgefragt und gesammelt, aber individuell, handschriftlich, als Stenogramm, in unterschiedlichen Lautumschriften und Erläuterungen festgehalten worden sind. Im Laufe der Sammelperiode wechselten auch die Sammler der einzelnen Ortspunkte und mit ihnen die Angaben für den Ort auf dem Zettel und die Lautumschrift. Das bedeutet aber, daß jeder dieser Belege einer aufwendigen Vorbearbeitung bedarf, bevor er im WBÖ zitierfähig interpretiert und eingearbeitet werden kann. Regelmäßig müssen 3 Hilfsmittel (Ortskatalog, eines der Fragebücher, Abkürzungsverzeichnis) zur Verifizierung eines Beleges herangezogen werden. Dieses zeit- und arbeitsintensive Vorbearbeiten des Belegmaterials wurde im Verlaufe der Beschleunigungsbemühungen um das WBÖ immer wieder diskutiert und konnte auch mit Hilfe studentischer Kräfte nur in wenig zufriedenstellender Weise verbessert werden.
Dieses formale Aufbereiten wiederholt sich bei jedem Stichwort, trotzdem ist die Merkfähigkeit für die einzelnen Siglen auch für gut eingearbeitete Mitarbeiter auf Grund der großen Vielfalt sehr beschränkt. Wir haben bis jetzt 150.000 unterschiedliche Orts- und Quelleneinträge registriert. Hier liegt ein großes Potential zur maschinellen Bearbeitung und wertvollen Zeitersparnis für die wissenschaftlichen Mitarbeiter.
Die Recherchen in den Fragebüchern sind ebenfalls zeitaufwendig, u.U. werden bei einem Stichwort einer konkreten Artikelstrecke über 80 verschiedene Fragebuchnummern angesprochen, sie bieten daher eine Automatisierung geradezu an.
2. Konzept für gezielten EDV-Einsatz
Die Bestrebungen seitens der ÖAW-Führung seit Mitte der 90er Jahre zu einer Beschleunigung der Publikation bzw. der Laufzeitbeschränkung des WBÖ auf 10 Bände innerhalb einer Publikationsfrist von 20 Jahren hat im Institut zu Überlegungen für ein neues Bearbeitungskonzept geführt. Die Redaktion des WBÖ ist davon ausgegangen, daß das größte Zeiteinsparungspotential bei der Automatisierung der oben erwähnten immer wiederkehrenden formalen Bearbeitungsschritte liegt. Die dafür notwendige Digitalisierung des Materials bedeutet außerdem zugleich eine Duplizierung der einzigartigen Unikate. Die Qualität und Lesbarkeit der z.T. über 100 Jahre alten handschriftlichen Belege ist mitunter schon sehr schwierig, nicht nur wegen der Kurrentschrift und Gabelsberger Stenogramme, die die nächste Forschergeneration wahrscheinlich nicht mehr lesen kann, sondern auch wegen bereits verblaßter Tinte und Tintenblei.Das 1993 genehmigte Konzept der Datenbank, finanziert aus Sondermitteln der ÖAW, sieht eine vollständige Erfassung der Belegsammlung vor, die von speziell erstellten Tustep-Programmen mit Hilfe von digitalen Nebendatenbanken weiterbearbeitet wird, bevor die eingegebenen Wortstrecken zum Artikelschreiben für die Publikation zugeteilt werden.
Um die Datenbank möglichst schon während des Entstehens für das WBÖ nutzbar machen zu können, wurde die Bearbeitung in mehreren Ausbauschritten geplant.
Dazu werden unsere Hauptkatalogbelege durch eine 1:1-Erfassung auf Datenbank mit dem Programm TUSTEP seit 1993 in eine nach verschiedensten Kriterien elektronisch sortierbare Belegdatei eingegeben, durch die das erwähnte zeitaufwendige Suchen, Sortieren usw. automatisiert werden kann. Ende 2000 wird ca. die Hälfte des noch zu publizierenden WBÖ-Materials elektronisch abrufbar sein, und 2006/2007 soll die digitale Erfassung abgeschlossen sein, vorausgesetzt daß die finanziellen Mittel weiter im geplanten Ausmaß zur Verfügung stehen.
Bereits jetzt werden für die laufende Artikelarbeit die eingegebenen Datensätze aufbereitet. Dazu stehen uns eine Reihe von im Institut erstellten Tustep-Programmen zur Verfügung, die die Automatisierung der oben beschriebenen Vorarbeiten ermöglichen. Diese Programme ergänzen, fügen ein, sortieren, duplizieren bzw. stellen Belege um, ändern Zitate usw. Dazu brauchen wir u.a. auch Subdatenbanken, die diese Informationen enthalten. Diese Informationsdateien sind im Laufe der Jahre von den Redaktoren zur Arbeitserleichterung angelegt worden und sind in handschriftlicher, maschinschriftlicher, digitaler und in gedruckter Form vorhanden.
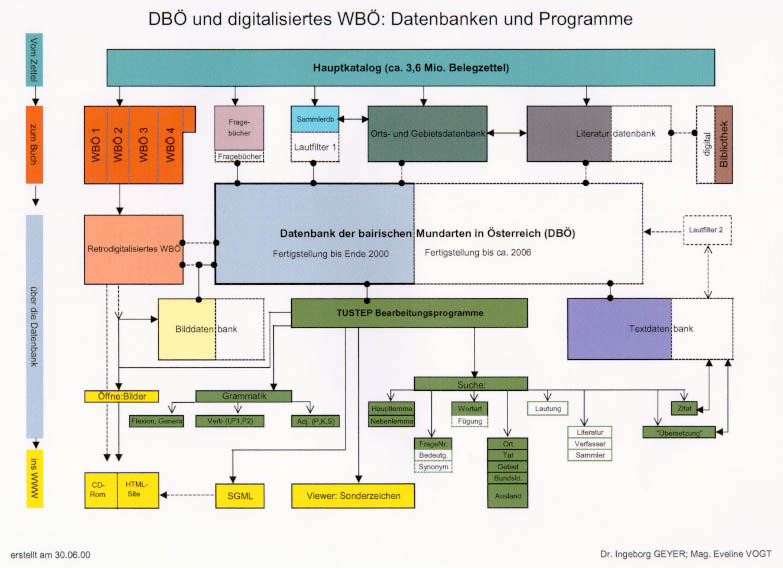
Wir haben diese zusätzlichen Entscheidungs- und Orientierungshilfen zu externen Tustep-Nebendatenbanken umgearbeitet, damit sie durch Einfügung mit Hilfe von Tustep-Programmdateien die Hauptdatenbank wirksam ergänzen bzw. unterstützen können (siehe die Graphik am Ende dieses Beitrags).
3. Masterdatenbanken
3.1. Belegdatenbank "DBÖ" (Kerndatenbank)
Wie schon gesagt, das Fundament für unsere Publikation sind die wertvollen mehr als 3 Mill. Unikate des Hauptkatalogs unterschiedlichster Qualität und auch unterschiedlichster Strukturen. Diese sollten möglichst originalgetreu digital wiedergegeben werden. Um alle Details später für eine strukturierte Datenbankabfrage richtig erfassen zu können, hat Frau Dr. Kühn eine Tustep-Eingabemaske entwickelt, die alle Beleg-Varianten berücksichtigt. "Alle" kann deshalb gesagt werden, weil zwei Rubriken vorgesehen sind, in denen man das unterbringen kann, was sonst nirgends hinpaßt, nämlich unter "Diverses" oder "Nota bene". Diese Kerndatenbank umfaßt derzeit die Buchstabenstrecke di/ti- bis he- und steht bereits intern für die Verfassung der WBÖ-Artikel und zu Recherchen nach bestimmten Bedeutungen, sachkundlichen Anfragen, lautlichen Besonderheiten usw. zur Verfügung. Ihre Aufbereitung für eine optimale Nutzung durch die wissenschaftlichen Mitarbeiter dient nicht nur dem Wörterbuchteam bei der Artikelarbeit, sondern auch für die Beantwortung externer Anfragen und wird mit Hilfe von weiteren Subdatenbanken und mit Tustep-Programmfolgen, überwiegend Tustep-Kopiere, bearbeitet. Die digitalen Daten ermöglichen auch andere Suchabfolgen als das unter bestimmten Stichworten eingeordnete Zettelmaterial. Mußte man bis jetzt immer das Stichwort wissen, unter dem man z.B. bestimmte Bedeutungen bzw. Synonyma erwartet, kann man über die Datenbank eine bestimmte Bedeutung suchen und bekommt die Lemmata als Ergebnis. Man kann auch die Fragebuchnummer als sachliches Kriterium verwenden und unter einer bestimmten Fragebuchnummer, z.B. "Faschingsbrauch am Faschingsdienstag" suchen und erhält alle diesbezüglichen Einträge vom Lotter gehen bis Bloch ziehen und Speibertag. Bis jetzt war man in so einem Fall auf interne Zettelverweise und eigene Sachkompetenz angewiesen. Diese Optimierung erreichen wir z.B. durch die Einfügung von Subdatenbanken, die unter Punkt 4 beschrieben werden.3.2. Textdatenbank
Als weitere wichtige Datenbank ist die elektronische Textdatenbank zu erwähnen. Sie beinhaltet über Glossare exzerpierte Literatur, vorwiegend historische Quellen wie die Österreichischen Weistümer (L 1) und regionale Mundartdichtung. Sie wurde in den letzten Jahren angelegt, wird bei Bedarf weiter ergänzt und dient in Hinkunft als Quelle für Textbeispiele im WBÖ. Die eingescannten Texte werden durch ein Kopiere-Programm so aufbereitet, daß zum jeweiligen Stichwort aus dem Glossar ein vollständiger Satz oder Absatz aus dem Textkorpus herauskopiert werden kann. An diese Textpassage ist auch gleich das neue gültige Zitat angefügt und durch die weiter oben erwähnte Sigle werden die über Zeichenfolgen gefundenen Belege nach Gebieten und Jahren geordnet und in einer Zwischendatei zur weiteren Bearbeitung abgelegt. Diese Hilfsdatenbank ist inzwischen kräftig angewachsen und auch für das Straffungs- und Beschleunigungskonzept wesentlich geworden. Bis jetzt mußten die in den Glossaren angegebenen Verweisstellen in der Originalstelle eingesehen, u.U. händisch exzerpiert werden, um im Material bei den einzelnen Bedeutungen mitbearbeitet werden zu können. Die neuen Straffungsrichtlinien sehen vor, bei den historischen Belegen aus jedem Jahrhundert nur mehr einen Beleg zu zitieren. Durch das Zusammenkopieren und Sortieren in der Zwischendatei hat der Bearbeiter in wirklich kürzester Zeit einen Überblick über die vorhandenen Belege und kann den treffendsten auswählen. Das Nebeneinander vieler gleichartiger historischer Belegstellen im Kontext erleichtert außerdem dem Bearbeiter die Bedeutungsfindung, ohne daß er die Originalquellen in der Bibliothek ausheben und die Belegstellen einsehen muß. Ähnliches gilt für die Mundartliteratur. Gerade die wertvollen älteren Quellen haben ein Glossar mit interessanten Sonderbedeutungen, aber keine Belegstellenreferenz. Auch hier kann jeder Bearbeiter über ein Kopiere-Programm, dem er die gewünschten Zeichenfolgen (bis maximal 9) eingeben muß, in z. Zt. 55 Quellen recherchieren.3.3. Bild- und Skizzendatei
Als sehr umfangreich stellt sich die Bild- und Skizzendatei (derzeit 1800) heraus. Sie wächst mit dem elektronischen Archiv. Alle Skizzen, Abbildungen auf den Sammlerbelegen werden eingescannt und als tif-Datei abgelegt. Die Abbildungen dienen sehr oft zum besseren Verständnis des beschriebenen Gegenstandes oder Vorganges, wie z.B. "Kopftuchbinden", "Garbenmännchen aufstellen" oder die diversen Typen von "Trage" als Transportgerät. Bis jetzt wurden dazu im WBÖ öfters Skizzen angeboten, jetzt wird - auch wegen der Straffung - auf die DBÖ verwiesen. Auf der elektronischen Eingabemaske ist der Bilddateiname eingegeben, so daß die Abbildung jederzeit auch aus der Tustep-Datei heraus abgerufen werden kann. Es ist daran gedacht, zum Abschluß des jeweiligen publizierten WBÖ-Bandes eine CD-Rom mit den vom WBÖ in die DBÖ ausgelagerten Daten und Images mitzuliefern.4. Subdatenbanken
4.1. Fragebücher
Durch die elektronische Einspeisung des "großen Fragebuchs" und anderer Frageaktionen mit Hilfe des Tustep-Programms "Einfüge" werden die auf den Belegen angegebenen Fragebuchnummern aufgelöst und aus der eingefügten Fragestellung wird die Bedeutung des am Zettel angegebenen Stichworts deutlich. Das in Fraktur gedruckte Fragebuch besteht aus 109 Fragebögen mit 16.747 Detailfragen, die aber unterschiedlich strukturiert sind, einmal mit Buchstaben, einmal mit römischen Zahlen gegliedert. Weitere Zusatzfragebögen mit über 700 Einzelfragen sind wieder anders strukturiert. Das Fragebuch wurde mit TUSTEP eingegeben und von Frau Dr. Kühn in die Einzelfragen gegliedert, der Text z.T. gekürzt bzw. der Fragebogenkopf wiederholt, um den Zusammenhang innerhalb des Fragebogens herzustellen. Bei Kürzungen des Originalfragebogentextes verweisen zwei Sternchen ** darauf, daß in der Datei "Fragebogen lang" noch weitere Informationen stehen; mit einem Tastenbefehl kann man in diese Datei im geteilten Bildschirm wechseln und wieder in die Ausgangsdatei zurückkehren. Die Auflösung der Nummernsigle auf den einzelnen Belegen durch die Einfügung der Fragestellung erspart viel Zeit beim Beantworten externer Anfragen bzw. bei der Bearbeitung der Artikel, besonders bei der Bedeutungsbeschreibung.4.2. Orts- und Literaturdatenbank
Für das WBÖ wurde Literatur aus Publikationen, die mundartliche, historische oder fachkundliche Texte aus dem Bearbeitungsgebiet beinhalten, exzerpiert. Diese Literaturbelege werden bei der Artikelbearbeitung gemeinsam mit den Sammlerbelegen bearbeitet. Daher brauchen diese Literaturbelege ebenfalls eine Orts- und Datiersigle, um nicht isoliert im nach Mundarträumen geordneten Datenmaterial herum zu liegen. Über 1.400 Literaturzitate und 3.000 Ortsangaben enthält die Datenbank bereits, dazu aber 150.000 unterschiedliche Zitierweisen. Es ist die wohl aufwendigste zusätzliche Datenbank, die ebenfalls Frau Dr. Kühn konzipiert hat. Die auf den Belegen verwendeten Orts- und Literaturangaben werden von ihr aufgelöst, eindeutig zugeordnet, mit "keys" versehen, die eine Sortierung nach unseren Ordnungskriterien ermöglichen, nämlich nach Gebieten und damit auch nach Mundarträumen. Gleichzeitig werden auch alle quellenkritischen Komponenten berücksichtigt. Durch den Vermerk des Sammlers auf dem Originalbeleg ist der Beleg genau datiert, er wird in Kurzsigle ins neue Zitat aufgenommen, genauso wie die Koordinaten unserer amtlichen, heute gültigen Ortsverzeichnisse, sodaß diese Punkte auch zum automatischen Kartenzeichnen verwendet werden könnten. Für dieses aufwendige Unternehmen wurde in TUSTEP ein Kopiere-Programm geschrieben, das über Austauschparameter die neue Zitierweise festlegt. Es wird eine enorme Qualitätsverbesserung und Benützungserleichterung für das Belegarchiv bringen. Zur Zeit beginnen wir mit einer schrittweisen Implementierung für die nächste Artikelstrecke.Diese Orts- und Literaturdatenbank erspart den Artikelverfassern nicht nur die aufwendige Lokalisierungsarbeit, sondern auch die verschiedenen Sortierungsarbeiten. Die vorsortierte HK-Datei wurde bis jetzt händisch einmal für die Verbreitungsangabe im Artikelkopf sortiert, dann für das Lautungskapitel nach lautlichen Kriterien ganz neu geordnet und zuletzt nach Bedeutungen zusammengestellt. Durch diese Sortiersiglen wird das geordnete Datenbankmaterial gleich in der richtigen Reihenfolge für die Verbreitung zusammengestellt, faßt dadurch auch automatisch die Mundartgebiete zusammen und mit den sogenannten "Artikelprogrammen" (= Tustep-Kopiere) kann man die Lautungen, Kontextbelege und Bedeutungen herausfiltern. Für die Bedeutungszusammenführung gibt es auch ein Kopiere-Programm, das die einzelnen Bedeutungen, die unterschiedlich auf den Belegen beschrieben sein können, abarbeitet, sodaß dem Bearbeiter keine Bedeutungsvariante bei der Zusammenfassung verlorengehen kann, z.B.: Stichwort Trage mit den Bedeutungsbeschreibungen: "Traggestell, Tragevorrichtung" usw.
Wichtig ist diese Einspeisung der Orts- und Literaturdatenbank außerdem, um die sogenannten "Null-Belege" nach den neuen Straffungsrichtlinien kennzeichnen zu können und vor der Artikelbearbeitung aussortieren zu können. Es werden Gebiete wie das Egerland und einzelne Ortspunkte in angrenzenden Ländern nicht mehr mitbearbeitet. In der Datenbank bleiben die Belege aus diesen Gebieten aber vorbearbeitet für andere wissenschaftliche Untersuchungen erhalten. Zur Erstellung dieser Datenbank haben wir weitere Hilfsmittel auf TUSTEP umgestellt, nämlich den "Ortskataster", "Sammlerkataster" und das Literaturverzeichnis.
4.2.1. Ortskataster
Der alte "Ortskataster", ein Zettelkasten aus der Monarchie, der alle Belegorte nach damals gültigen Orts- und Ländernamen umfaßte und auch das bayerische Staatsgebiet mit einschloß, wurde in den 70er Jahren von uns umgearbeitet und maschinenschriftlich erfaßt. Viele Ortsnamen waren nicht mehr gültig, liegen jetzt auf fremdem Staatsgebiet und werden anders geschrieben. Zum Teil waren diese Ortsnamen nur eindeutig mit der Sammlersigle oder der Katalogzettelfarbe zu lokalisieren. Dazu wurden jetzt einheitliche Abkürzungen und regionale Zuordnungen getroffen. Dieses 50 Seiten starke Manuskript war eine wertvolle Orientierungshilfe für die Erstellung der elektronischen Datei.
4.2.2. Sammlerkataster
Die Dokumentation der Sammler in einer eigenen Datei gibt Auskunft über Art, Umfang und Güte der Sammlung, eventuell auch einen kurzen Lebenslauf mit Beruf des Sammlers und den Zeitraum, in dem er für die damalige Wörterbuchkanzlei tätig war. Auch über graphische Besonderheiten sind Anmerkungen enthalten. Die sind für die lautliche Interpretation der Belege notwendig. Ein Sammler schreibt z.B. alle verdumpften a mit �, der andere mit darübergesetzte Ringlein � oder Stern *. Aus demselben Gebiet gibt es dann einen Sammler, der das � für helles a verwendet usw.
4.2.3. Literaturverzeichnis
Das publizierte Literaturverzeichnis wurde um die Anmerkungen in der Kartei vermehrt und gibt Auskunft, wann, von wem und was aus den einzelnen Werken exzerpiert wurde. Für die Sigle in der Datenbank ist das weniger relevant, da ist es wieder wichtiger, ob der Beleg aus einer Dissertation und daher phonetisch gesichert ist, oder ob er aus einem Mundartgedicht stammt. Hier ist wieder das Alter des Belegs und die Gebietszuordnung wichtig, die sich oft nicht mit dem Titel deckt, z.B. Gedichte in oberösterreichischer Mundart sind meistens auf eine Gegend beschränkt. Das Erscheinungsjahr im Titel muß nicht mit dem Alter des Textes identisch sein, beides kann für die Interpretation eines Belegs sehr wichtig werden und ist in der für die DBÖ festgesetzten Literatursigle enthalten.
4.3. Pflanzennamenkatalog
Für das Wörterbuch der bairischen Mundarten in Österreich wurde ein eigener Katalog der mundartlichen Synonyma für heimische Pflanzen, Sträucher und Bäume angelegt. Dies ist eine einzigartige Sammlung aus dem bairisch-österreichischen Sprachraum und den ehemaligen angrenzenden deutschsprachigen Gebieten, die nicht nur Zeugnis der mundartlichen Vielfalt bei der Benennung der im bäuerlichen Lebenskreis wichtigen bzw. nützlichen Pflanzen gibt. Auch die Artenvielfalt und das Vorkommen seltener, jetzt schon ausgerotteter Pflanzen werden dokumentiert. Überaus interessant ist dabei die Benennungsmotivation für Pflanzen. Sie wird u.a. durch ihre Verwendung, ihre Nützlichkeit im bäuerlichen Haushalt, ihr Aussehen und teilweise auch durch die Funktion im bäuerlichen Brauchtum im Jahreslauf bestimmt.Die Stichworte für den Katalog gehen von den lat. Pflanzennamen aus. Der Katalog umfaßt über 2.000 lateinische Stichworte. Unter dem jeweiligen Stichwort befinden sich alle im Verbreitungsgebiet des WBÖ üblichen Mundartausdrücke für die betreffende Pflanze, insgesamt ca. 20.000 Mundartbenennungen. Der Eintrag in die Archivkarte erfolgte in mundartlicher Umschrift mit Gebietszuweisung.
Um auch die Pflanzennamenbelege mit der Dialektdatenbank verknüpfen zu können, ist eine digitale Aufbereitung notwendig. Nach dieser Eingabe wird nicht nur eine effizientere Bearbeitung für die WBÖ-Publikation möglich sein, sondern es ergeben sich auch neue Möglichkeiten der Recherchen für andere Wissenschaftler wie Volkskundler, Botaniker, Linguisten und interessierte Laien, wie z.B. Heimatforscher. Für sie kann dann ein Ausdruck aller mundartlichen Pflanzennamensynonyma eines Ortes, Gebietes bzw. Bundeslandes erstellt werden.
Dazu ist ein Eintrag der einzelnen mundartlichen Synonyma und ihrer Verbreitungsgebiete in Datenbankmasken mit aktualisiertem lateinischem Stichwort und Lemma-Auszeichnung notwendig. Ein Drittel des Katalogs ist bereits aufgearbeitet.
4.4. Lemmaliste
Ein Desiderat ist noch eine Gesamtlemmaliste beginnend von A. Dazu haben wir die ersten vier Bände des WBÖ digitalisiert. Die Umarbeitung zu einer struktierten Tustep-Datei ist z. Zt. eine Geldfrage. Sollte dies bald gelingen, könnte sozusagen eine wachsende Lemmaliste mit Bedeutungen in die Homepage gestellt werden. Für das eingegebene Material gibt es bereits eine Lemmaliste mit Bedeutungen, allerdings unbearbeitet.4.5. Verweise
Bereits abgeschlossen und eingearbeitet in die Kerndatenbank ist die Erfassung des Verweiskatalogs. Diese Nebendatenbank beinhaltet alle Stichworte, auf die von den Bänden 1-4 verwiesen wurde, sei es als Synonym, als Bestimmungswort oder aus sachlichen Kriterien u. ä. Diese Datei dient auch zur Lemmafestlegung.4.6. Lautinterpretationsdatei
Für noch längere Zeit ein Desiderat wird die Interpretation der einzelnen Lautschriften der ca. 2.300 Sammler bzw. der Fachliteratur bleiben. Diese Datenbanken sind in der beigegebenen Graphik (am Ende dieses Beitrags) noch weiß gehalten und wurden von mir behelfsmäßig "Lautinterpreter" genannt. Damit wollte ich ausdrücken, daß wir nicht die Originallautungsbelege umschreiben wollen, sondern nach eingehender Analyse die Schreibung einem bestimmten Lautzeichen unseres WBÖ-Transkriptionssystems zuweisen. Schneller und daher auch früher werden wir Interpretationsprogramme für die Fachliteratur, wie Mundartwörterbücher, Dissertationen und Mundartdichter erstellen können, um z.B. die graphematisch unterschiedlich ausgezeichneten hellen bzw. verdumpften a bei der maschinellen Verarbeitung richtig zuordnen zu können. Die schon erwähnten Mundartdichter verwenden individuell z.B. a mit Gravis einmal für helles a, einmal für dumpfes a. Für eine deutliche Beschleunigung der Publikation sind diese beiden Hilfsdatenbanken aber ebenso wichtig wie für die bequeme Benützung unseres Archivs durch Außenstehende. Die umgesetzte Belegstelle wird besonders gekennzeichnet nachgestellt, entsprechend etwa der gebräuchlichen Zitierweise "sprich".5. Arbeitsablauf mit EDV-Einsatz
Diese zugegebenermaßen mit viel Aufwand erstellten Hilfsmittel zur einheitlichen Strukturierung für die Datenbank unterstützen bereits die Artikelabfassung.Die vom Artikelbearbeiter übernommenen Belegstrecken werden - wie schon beschrieben - mit diesen Subdateien vorbearbeitet und nach den WBÖ-Kriterien sortiert. Dazu haben wir ein Tustep-Sortierprogramm mit mehreren umfangreichen Sortierschlüsseln geschrieben.
Jedem Mitarbeiter steht eine edv-mäßig erstellte Lemmaliste aus allen elektronisch erfaßten Stichwörtern und deren Bedeutung zur Verfügung. Sie wird mit einem Kopiere-Programm erstellt und aus Zeitgründen nicht nachbearbeitet. So kommen z.B. "Gestell zum Tragen, Vorrichtung zum Tragen" jeweils als eigene Bedeutung. Gleichzeitig kann der Bearbeiter in das bereits elektronisch verfügbare Material einsehen, nach ähnlichen Lemmata, Lautungen oder Bedeutungen suchen. Er wird z.B. beim Verfassen der Artikel der Lemmastrecke von track- auch trag- durchsehen und Belege eventuell umlemmatisieren und neu ordnen. Auch statistische Auswertungen sind möglich.
Durch die umfangreichen automatisierten Vorbearbeitungen kann sich der Artikelbearbeiter ganz auf die eigentliche Tätigkeit konzentrieren, nämlich das wissenschaftliche Bearbeiten und Interpretieren der einzelnen Belege und deren Zusammenfassung in zusammenhängende zeilenorientierte Wortartikel. Auch dabei unterstützt TUSTEP. Diese schon weiter vorne erwähnten Artikel-Kopiere-Programme sind als Programmdatei über eine Mausleiste aktivierbar. Für das Zusammenfassen von Stichwortgruppen, Bedeutungen, grammatikalischen Kategorien usw. stehen für jeden Bearbeiter über Mausklick anwendbare Programmfolgen zur Verfügung, ebenso für individuelle Recherchen aus der Textdatenbank.
Zur Zeit werden die Wörterbuchartikel für das gedruckte WBÖ noch auf dem Programm Scientex geschrieben, das eine sehr anwenderfreundliche Benutzeroberfläche in graphischer Hinsicht besitzt. Es können praktisch alle wichtigen Sonderzeichen inklusive Kursiv- und Fettdruck auf dem Bildschirm ohne großen Aufwand dargestellt werden; dadurch ist schon beim Ausarbeiten eine angenehme Vorlage ohne sichtbare Setzeranweisungen und die Darstellung der Sonderzeichen auf dem Bildschirm gewährleistet. Die Druckerei hat die nötigen Umsetzprogramme, sodaß wir beinahe fehlerfreie Ausdrucke bekommen.
Für den externen Zugriff auf unsere Daten haben wir zum Ausdruck unserer Belege ein elegantes Tustep-Druckprogramm geschrieben, das die Lemmata fett druckt und die Belegstellen kursiv samt aller Sonderzeichen darstellt. Dieses Druckprogramm wurde leicht modifiziert und ergibt jetzt im Viewer ebenfalls ein ansprechendes Bild von Tustep-Daten mit vielen Sonderzeichen. Eine weitere Modifikation erzeugt SGML-Dateien, die über Internet abgerufen werden können. Die Sonderzeichen werden browser-bedingt zur Zeit nur z.T. umgesetzt.
1993 wurde das Konzept für die Österreichische Dialekt-Datenbank mit drei Zielsetzungen formuliert. Zum Abschluß sollte erreicht werden:
Gleichzeitig wird aus der Datenbank ein konventionelles, umfangmäßig auf 10 Bände geplantes gedrucktes Wörterbuch abgeschlossen, das auf zusätzliche Daten und Images in der DBÖ verweist. Wir erwarten, daß die Publikation neugierig macht, auf die wissenschaftlich aufbereitete Datenbank zuzugreifen.
Diese Datenbank könnte zu einem ständig weiter ausbaufähigen elektronischen Online-Medium werden und mit anderen Wörterbüchern vernetzt werden, um Martin Schröder (L 3) zu zitieren. TUSTEP ist auf dem Weg dorthin unser wichtigstes Programm-Werkzeug.
Erwähnte Literatur:
(L 1) Österreichische Weist(h)ümer. Gesammelt von der (kaiserlichen/österreichischen) Akademie der Wissenschaften. Wien 1870f. (zurück)
(L 2) Schmeller, Johann Andreas: Bayerisches Wörterbuch. Stuttgart und Tübingen 1827-1837. 2. Aufl. von G. Karl Frommann, 2 Bde, München 1872-1877. (zurück)
(L 3) Schröder, Martin: Brauchen wir ein neues Wörterbuchkartell? Zu den Perspektiven einer computerunterstützten Dialektlexikographie und eines Projekts "Deutsches Dialektwörterbuch". In: ZDL 64 (1997) S.57-66. (zurück)
(L 4) Schweizerisches Idiotikon. Wörterbuch der schweizerdeutschen Sprache. Bearbeitet von Friedrich Staub, Ludwig Tobler, Albert Bachmann u.v. a. Frauenfeld 1881f. (zurück)
(L 5) Wörterbuch der bairischen Mundarten in Österreich, hg. im Auftrag der Österreichischen Akademie der Wissenschaften, Wien 1963f. (zurück)
aus: Protokoll des 78. Kolloquiums über die Anwendung der EDV in den Geisteswissenschaften am 5. Februar 2000