
Harry Graf Kessler (1868-1937) war eine singuläre Erscheinung in einem besonders bewegten Abschnitt der europäischen Zeit- und Kulturgeschichte. Sein Tagebuchwerk (1880-1937) ist eine einzigartige Quelle für die Erforschung der politischen Geschichte, der Kunst-, Kultur- und Literaturgeschichte seiner Zeit. Es ist fortlaufender Zeitbericht und Zeitkommentar, geschrieben von einem unerbittlich scharfen Beobachter, sensiblen Denker und homme de lettre. Die Tagebücher Kesslers sind stilistisch gefestigte Berichte mit literarischem Wert. Sie sind auch aufgrund der außergewöhnlichen Länge von Eintragungs- wie Berichtszeit ein singulärer Typus der Gattung Tagebuch.
Angesichts des starken Interesses von Forschung, Publizistik und Öffentlichkeit an den Tagebüchern des Grafen Kessler wird es höchste Zeit, das Tagebuchwerk insgesamt zugänglich zu machen. Das Tagebuch ist eine einmalige Prosopographie der Berichtszeit (ca. 12.000 Namensnennungen); schon dieses Quellenaspektes wegen muß es vollständig wiedergegeben und aus dem selben Grunde wenigstens knapp erläutert werden. Nur als ganzes wird sein Quellenwert wirksam für die Erforschung der politischen Geschichte, der Gesellschaftsgeschichte, der Geschichte von Kunst, Kunstgewerbe, Literatur, Theater und Film. Die Tagebücher sind als Gattung ebenso interessant wie als Quellen- und Nachschlagewerk für vielfältige Forschungen unverzichtbar.
Ein Projekt zur Editionsvorbereitung hat von Frühjahr 1994 bis Ende 1999 die wissenschaftliche Transkription erarbeitet und Arbeitsregister erstellt.
Angestrebt wird eine Hybrid-Edition als neuer Typus einer wissenschaftlichen Quellen-Edition: Der Text wird in behutsam redigierter Form gedruckt veröffentlicht (9 Bände). Diese Fassung dient als Forschungs- und Leseausgabe.
Vorgesehen sind ausführliche Einleitungen zu den einzelnen Bänden und teilweise erläuterte Register. Stellenkommentare in Form von Fußnoten soll es nur in einzelnen Fällen geben, dort wo es für das Verständnis und ggf. für die Registerbenutzung erforderlich ist, etwa wenn Kessler sich bei Namen irrt oder wenn griechische und lateinische Passagen übersetzt werden müssen. Jeder Band soll ein eigenes Namensregister haben.
Neben der gedruckten Fassung soll eine elektronische Publikation als zusätzliches Hilfsmittel für die Forschung erscheinen, welche die Funktion der Tagebücher als Nachschlagewerk erfüllt. Die geführten Register zu Personen, Werken, Orten, Plätzen, Körperschaften und Zeitungen/Zeitschriften sollen zusammen mit einer geeigneten Recherchesoftware auf der CD-ROM die wissenschaftliche Recherche erleichtern. Faksimiles exemplarischer und singulärer Tagebuchseiten sowie der zahlreichen Beilagen ergänzen die elektronische Publikation und machen den Quellen-Charakter des Tagebuches sichtbar.
In der Form einer Hybrid-Edition können alle Facetten des Tagebuchwerkes Harry Graf Kesslers gezeigt werden. Quellencharakter und Diaristik kommen gleichermaßen zum Tragen.
Da die Veröffentlichung dringend nachgefragt wird, ist es das Ziel des Projektes, den Text zügig zu publizieren. Die Buchausgabe erscheint ab Oktober 2002 in einem halbjährlichen Rhythmus. Dem ersten Band liegt eine CD-ROM mit dem Preprint des gesamten Textes des Transkriptionsprojektes in unbearbeiteter Form bei. Mit Erscheinen des letzten Bandes wird der Preprint ersetzt durch die endgültige Forschungsfassung mit Retrievalwerkzeugen und zugehörigen Materialien.
(Eine ausführliche Beschreibung der Projektziele, der auch die vorstehenden Abschnitte entnommen wurden, findet sich unter http://www.dla-marbach.de/einricht/projekte/hgk/hgk_0.html)
Grundlage der Erfassung/Transkription sind 57 handschriftliche Tagebuchbände mit etwa 11.000 engbeschriebenen Seiten.
In der Transkriptionsphase sind ca. 600 Dateien im Word-97-Format entstanden, in denen Strukturelemente und Registerbegriffe (in Vorlageform) konsequent mit Absatz- und Zeichenformaten ausgezeichnet wurden. Die Register der Tagesdaten für Personen, Körperschaften, Werke, Zeitungen/Zeitschriften und Orte wurden als MS-Access-Datenbank geführt.
Anfang des Jahres 2000 haben die Editionsarbeiten auf dieser Grundlage begonnen.
Das Register des Transkriptionsprojektes (DaReT HGK) wurde übernommen und wird in der MS
Access-Datenbank EDDA weitergepflegt. Jeder Name in EDDA besitzt einen eindeutigen numerischen
Schlüssel, der als key-Attribut im XML-Text wiederkehrt.
Der vorliegende Transkriptionstext (MS Word) wird von einer Mitarbeiterin per Word-Makro in ein XML-Format überführt, dem die DTD TEI-Lite zugrunde liegt (mehr zur TEI und zur DTD
weiter unten). Das Makro konvertiert die Druckformate in entsprechende
TEI-Elemente; tabellarische Meta-Informationen zur Kollation werden so gut wie möglich in den
TEI-Header übernommen. Die Mitarbeiterin validiert die Datei nach syntaktischen Aspekten und
beseitigt offenkundige, auf Word beruhende Schachtelungsschwächen. Danach wird die XML-Datei
für die wissenschaftliche Arbeit freigegeben, die zu einem großen Teil darin besteht, die
ausgezeichneten Registerelemente (Namen) mit den normierten Einträgen der Datenbank zu
identifizieren, also die korrekten key-Attribute zuzuordnen. Die Word-Datei wird
schreibgeschützt und steht nur noch für Vergleiche zur Verfügung.
Die Datenpflege erfolgt mit dem XML-Editor XMetaL 2.0 der Firma Softquad (die künftig allerdings von der Corel Corporation übernommen werden soll).
Für Korrekturausdrucke und die Vorschau am Bildschirm werden Microsofts Internet Explorer sowie das Tübinger System von Textverarbeitungsprogrammen TUSTEP genutzt. Für die Datenumwandlung von XML nach HTML oder in die Syntax des TUSTEP-Satzprogramms werden XSLT-Stylesheets benutzt, die im Detail weiter unten beschrieben werden.
Die konvertierten Altdaten sind syntaktisch ärmer als die beabsichtigten TEI-Strukturen, so daß der Formatwechsel als Bereicherung empfunden wird. Die alten Druckformate waren jedoch Anhaltspunkt für die Gestaltung der Cascading Stylesheets (CSS).
Anführungszeichen werden allerdings wie in den Altdaten als Zeichen-Entities (anstelle von Elementen) weitergeführt, was als Bequemlichkeit gedeutet werden kann, angesichts der speziellen Aufgabenstellung einer exakten Edition aber vielleicht auch sachgerechter ist.
Da dies die erste Anwendung dieser Art im Hause darstellt und somit keine bestehenden Verfahren weitergeführt werden mußten, konnte XML gegenüber einer klassischen SGML-Lösung der Vorzug gegeben werden. Ausschlaggebend waren dabei die folgenden Überlegungen:
Für SGML sprach der fortgeschrittene, selbstdokumentierende Änderungsmechanismus, mit dem die Module der SGML-basierten TEI-DTD an lokale Verhältnisse angepaßt werden können. Dies war zu Projektbeginn in der XML-Variante nicht möglich. Angesichts des geringen Änderungsbedarfes scheint der pragmatische Ansatz, direkt den Code der XML-basierten DTD zu modifizieren, jedoch gerechtfertigt (zumal diese Änderungen mit dem "Revision Control System" RCS gepflegt werden).
Im Juni 2001 hat das TEI-Consortium zudem eine vollständig XML-kompatible (allerdings noch vorläufige) Version seiner DTD (TEI P4) veröffentlicht.
Die Text Encoding Initiative (TEI) hat Guidelines for Electronic Text Encoding and Interchange und dazugehörige DTDs entwickelt und stellt sie der Öffentlichkeit kostenlos zur Verfügung. Auf diesen wertvollen Vorarbeiten konnte das Kessler-Projekt aufbauen.
Die verwendete DTD hgkdiary.dtd orientiert sich dabei weitgehend an der Vorlage TEI-Lite, die ihrerseits eine populäre, vereinfachte Untermenge der vollen TEI-DTD darstellt.
TEI-lite enthält immer noch wesentlich mehr Elemente, als im Projekt genutzt werden. Umgekehrt
bietet selbst die volle TEI-DTD nicht alle benötigten Elemente: Es gibt zwar zusätzlich zum
allgemeinen <name>-Tag das speziellere und interessante <persname>,
entsprechend benannte symmetrische Elemente für Werke, Zeitschriften usw. fehlen jedoch.
Als Lösung wurden unspezifische Elemente wie <div> oder
<rs> (referring string) benutzt und ihre Bedeutung in das type-Attribut
verlagert. So steht nun z.B. <rs type="per"> für eine Person, <rs
type="wrk"> für ein Werk und <div type="entry"> für den
Tagebucheintrag eines Tages.
Kompatible Abweichungen
Es gibt mehrere kompatible Änderungen, bei denen die grundsätzlich freie Wertemenge von
Attributen auf eine endliche Menge beschränkt wurde. Dies gilt etwa für das
rend-Attribut (Rendering) im <hi>-Tag (Highlighting), das im Projekt nur die
Werte "sub | sup | ul.1 | ul.2 | ul.3 | ul.4 | ul.5 | other" für tatsächlich vorkommende
Unterstreichungen etc. annehmen darf. Ähnliches gilt für die Namenskürzel verantwortlicher
Bearbeiter usw.
Nicht-kompatible Abweichungen
TEI-lite enthält einige Einschränkungen in der DTD, die für uns nicht nachvollziehbar
sind und die wir durchbrechen mußten, um die vorliegende Textbasis kodieren zu können. So ist
etwa innerhalb einer <dateline> ursprünglich kein <hi> oder
<note> möglich.
Der Datentyp des hand-Attributs (Schreiberhand) z.B. im <hi>-Element
wurde von IDREFS auf eine vordefinierte Wertemenge geändert, da TEI-Lite das Element
<handList> zur Definition der Schreiberhände überhaupt nicht kennt.
Im Dateisystem bündeln Unterverzeichnisse die Quelltexte jahresweise, jede Datei nimmt dann in der Regel die Tagebucheinträge eines Monats auf (zum Beispiel: 1898\1898_05.xml).
Jede Datei bildet eine syntaktisch eigenständige XML-Struktur mit dem Top-Level-Element
<TEI.2>. (Für eine spätere Gesamtverarbeitung aller Dateien kann das umfassende
<teiCorpus.2> zum Einsatz kommen.)
Innerhalb jeder Datei gibt es zwei Hauptteile: den <teiHeader>, der
Metainformationen und insbesondere die Änderungsgeschichte (<change>) aufnimmt
sowie den eigentlichen <text>, der den Transkriptionstext enthält.
Jeder Monat wird ausgezeichnet in der Form <div type="month" id="m-1898-05"> und
enthält seinerseits die verschiedenen Tagebucheinträge, die mit <div type="entry"
id="d-1898-05-03"> eingeleitet werden. In der Regel entspricht ein Tagebucheintrag einem Tag.
Das id-Attribut wird als Referenz für die Registerdatenbank und als Sprungziel für
Hypertext-Navigation genutzt. Wenn tagesübergreifende Einträge auftreten, werden leere
Hilfselemente (<anchor>) eingefügt, damit in jedem Fall ein konkretes Sprungziel
existiert, bei mehreren Einträgen zu einem Tag wird die Zählung im id-Attribut
entsprechend erweitert.
Jeder Tagebucheintrag beginnt mit der Sequenz
<opener><dateline>, die Datum und Schreibort kennzeichnet und als
Überschrift gesehen werden kann. Daran schließen sich in Absätzen die Notizen Kesslers
an, die von editorischen Bemerkungen und Ergänzungen verschiedenen Typs (<note>)
durchsetzt sein können.
Inhaltsorientierte Struktur-Elemente überwiegen bei weitem, jedoch muß die Edition auch
bedeutungstragende Layout-Eigenschaften des Ausgangstextes abbilden. Dazu gehören etwa Streichungen,
nachträgliche Eintragungen und Unterstreichungen (<del hand="...">, <add
hand="...">, <hi rend="ul.2">).
Eine Herausforderung stellen die vielfältigen Abschriften, Zeitungsausschnitte, Photos,
Zeichnungen, Postkarten etc. dar, mit denen Kessler sein Tagebuch angereichert hat. Sie müssen
sowohl inhaltlich als auch physikalisch beschrieben werden. Hier kommt das allgemeine Element
<seg> (Segment) zum Einsatz, das über type="article | card | copy | drawing | hgk
| photo | other" und subtype="fixed | loose" weiter spezifiziert werden kann. (Zu
jedem type existiert eine .imp-Variante ("important") - zum Beispiel drawing.imp - die
wichtige Beilagen kennzeichnet, die in der Druckausgabe als solche erscheinen sollen.)
Typische Elemente
Neben den bereits erwähnten Textelementen sind die Namen von Personen, Orten, Werken etc.
die typischen Elemente der Anwendung. Alle Namen werden mit dem allgemeinen <rs>
(referring string) ausgezeichnet, das im Gegensatz zu dem ebenfalls möglichen
<name> nicht zwangsläufig ein "proper noun" (TEI-Guidelines 6.4.1) sein muß.
Wie bereits oben beschrieben, wird die semantische Qualität einen Namens durch sein
type-Attribut ausgedrückt: Hier sind "cor | cor.loc | loc | loc.wrt | mag | per | pla |
wrk" für Körperschaft, ortsgebundene Körperschaft, Ort, Schreibort, Periodikum,
Person, Platz und Werk möglich.
Jeder Name im Text muß identifiziert und auf eine normierte Ansetzungsform abgebildet werden.
Diese Normdaten werden außerhalb von XML in einer MS-Access-Datenbank geführt und enthalten
zusätzliche Informationen wie Lebensdaten, Verweisungsformen, Recherche-Erkenntnisse. Die Verbindung
wird über das key-Attribut hergestellt, das den alphanumerischen eindeutigen
Datenbankschlüssel enthält, wenn ein Name bearbeitet und identifiziert ist.
Das key-Attribut der Namen soll später für die Navigation in das
Namens-Register oder eine automatische Datenbankrecherche verwendet werden. Umgekehrt dienen die
id-Attribute der Tagebucheinträge als Sprungziel vom Register auf den Text. Hier wird jedoch
vorläufig nur der Tag selbst oder das erste Auftreten eines Namens das Ziel bilden.
Wichtige Beilagen (Zeichnungen, Photos etc.) sollen als Graphiken eingebunden werden. Dies geschieht
über das <figure>-Element, dessen entity-Attribut auf eine externe
Graphikdatei verweist.
Präsentation typischer Elemente mit CSS
Die Pflege und Präsentation der typischen Strukturelemente wird durch Cascading Stylesheets Level 1 (und teilweise Level 2) innerhalb von XMetaL optimal unterstützt
(XSLT kommt erst beim Export der Daten zum Einsatz).
Typographie und Farben werden zur leichten optischen Unterscheidung der Elemente und -Typen verwendet.
Durch komplexe CSS-Selektoren wird erreicht, daß alle Elemente, die noch der Bearbeitung
bedürfen, mit einem grauen Hintergrund dargestellt werden (etwa, wenn noch kein
key-Attribut vergeben wurde). So läßt sich die Arbeitsvorschrift "Alle grauen Stellen
müssen beseitigt sein" bereits optisch schnell überprüfen. XMetaL paßt diese
Darstellung dynamisch während des Edierens in Echtzeit an, was einerseits erwünscht ist,
andererseits aber auch Performanceprobleme mit sich bringt.
CSS werden auch für eine möglichst passende Darstellung des universell verwendeten
rend-Attributs (rendering) verwendet.
Das Projekt verwendet den üblichen MS-Windows-Zeichensatz und greift für Sonderzeichen auf Entities zu, die in separaten Deklarationsdateien (iso-lat2, iso-dia, iso-num, iso-pub, iso-grk1, iso-grk2, iso-grk3, iso-grk4, iso-cyr1, iso-cyr2.ent) auf numerische Unicode-Werte abgebildet werden.
Die Kodierung fortlaufender griechischer Zitate, welche korrekte und typographisch ansprechende Ausgabe sowohl in allen Editoren und Browsern sowie im Druck gewährleistet, ist jedoch noch nicht gelöst.
XMetaL
Der Editor XMetal 2.0 hat sich grundsätzlich als Glücksgriff für das Projekt erwiesen, da seine verschiedenen Ansichten den Eingabe- und Pflegeanforderungen optimal gerecht werden. Die layout-orientierte "Normal View" hat die Akzeptanz der Winword-gewohnten Mitarbeiter wesentlich befördert.
Es gibt jedoch auch einige Kritikpunkte an XMetaL:
XMetaL bietet zum Glück durch sein ausgefeiltes Document-Object-Model sowie die differenzierte Ereignissteuerung zahlreiche Ansatzpunkte, eigene Javascript- (oder Visual-Basic-) Routinen zu integrieren. Damit ließen sich für die genannten Einschränkungen Workarounds programmieren. Der Aufwand dafür ist aber erheblich, und viele Punkte sollten eigentlich vom Hersteller behoben werden.
Inzwischen ist XMetal 2.1 mit erweiterter Unicode-Unterstützung verfügbar, doch erwies sich die neue Version bei ersten Tests als inkompatibel zu den bestehenden Entity-Deklarationen und wurde deshalb zunächst nicht produktiv gemacht, zudem auch die CSS-Performance-Probleme bestehen bleiben.
Browser
Bei Projektstart war nur Microsofts Internet-Explorer (MSIE) in der Lage, XML und XSLT-Daten im Client korrekt zu verarbeiten. Inzwischen stellt Netscape 6.1 bzw. Mozilla 0.9.x eine Alternative dar, die bisher aber nicht systematisch getestet wurde. MSIE 5.x ist deshalb vorläufig der Standard-Browser im Projekt, bleibt aber auch nicht ohne Kritik:
type-Attribut per Style gar nicht auswerten. Man muß beispielsweise auf ein
zusätzliches XSL-Stylesheet ausweichen, das das type-Attribut in class
transformiert. Die Einbindung von XSL-Stylesheets in die Browser-Preview in XMetaL ist allerdings nicht
trivial, da auch hier die Standardmakros des Herstellers ziemlich modifiziert werden müssen.Bereits für die integrierte Voransicht im Browser muß eine XSL-Transformation vorgenommen werden, da MSIE den Attributreichtum des XML-Quelltextes mit seinen CSS1-Mitteln nicht auswerten kann. Diese Transformation erfolgt selbsttätig durch den Browser, der die Zeile
<?xml-stylesheet href="../../dtd/hgkdiary-html.xsl" type="text/xsl"?>
im Dateikopf entsprechend auswertet. Da XMetaL 2.0 XSLT nicht unterstützt, stört diese Zeile
nicht; XMetaL verwendet zur Anzeige immer das standardmäßig erwartete .CSS-Stylesheet.
Man kann die XML-Dateien auch außerhalb von XMetaL direkt in MSIE korrekt betrachten. Die Quelltext-Ansicht zeigt dabei trotz der internen Umwandlung nach HTML den ursprünglichen XML-Code.
Da die entsprechenden XSL-Stylesheets schon für die Browser-Vorschau entwickelt werden mußten, kann die ähnliche makrogesteuerte Funktion "als HTML-Datei speichern" relativ leicht in XMetaL integriert werden. (Es gibt jedoch subtile Unterschiede in der Arbeitsweise des MSXML-Parsers zwischen der impliziten und der scriptgesteuerten XSL-Transformation, die einige Experimente erforderte.) Auf diesem Weg entsteht eine separate HTML-Datei, wie sie in ähnlicher Form auf der ersten CD-ROM zu finden sein werden.
Das Grundprinzip der XSL-Transformation kann nicht nur HTML-Code erzeugen, sondern die ursprünglichen Elemente z.B. auch in die Syntax des TUSTEP-Satzprogramms überführen.
Auch hier wurden zwei Modi implementiert: "Als TUSTEP abspeichern" erzeugt eine unabhängige TUSTEP-Datei für die freie Bearbeitung in TUSTEP, "Mit TUSTEP setzen" stößt einen automatischen Ablauf (mit temporären Dateien) an, an dessen Ende nach kurzer Wartezeit eine typographisch hochwertige Postscript-Datei in der Ghostview-Vorschau steht.
Die key-Attribute der Namen bleiben in TUSTEP unsichtbar erhalten. Damit ist es
prinzipiell möglich, die ausgebauten Registerfunktionen von TUSTEP für die Erstellung von
Namensregistern zu nutzen.
Erst mit TUSTEP sind die erwähnten Probleme in der Darstellung der Sonderzeichen gelöst.
Die Umwandlung für das TUSTEP-Satzprogramm umfaßt im einzelnen folgende Schritte:
WSHShell.Run() die TUSTEP-Startdatei
preview.tsd, die die üblichen Aufrufparameter festlegt und außerdem die Umgebungsvariable
PREVIEV=true setzt.PREVIEV=true gefunden wird, wird die Segmentdatei
(Makrosammlung) hgktools.seg geladen und das Makro #$PREVIEW ausgeführt. Andernfalls (wenn
der TUSTEP-Start nicht über preview.tsd erfolgte) kann eine ganz normale interaktive
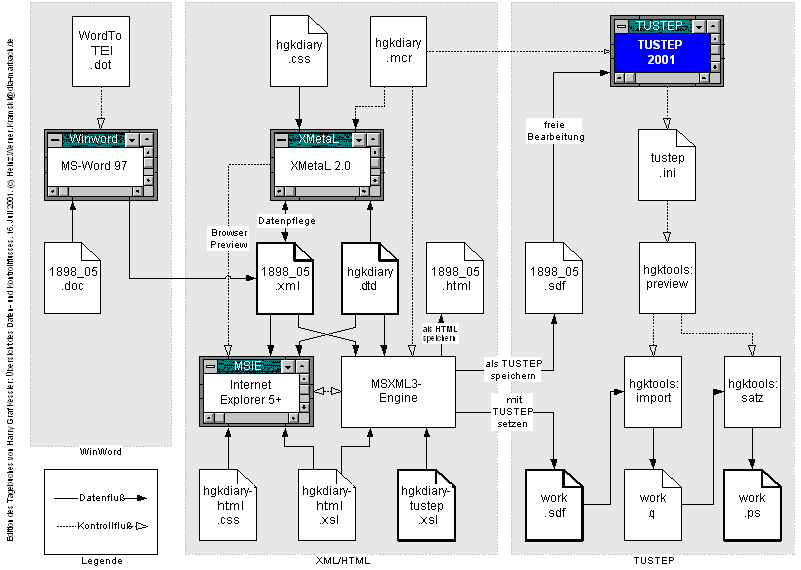
TUSTEP-Sitzung in dem Arbeitsverzeichnis stattfinden.Die folgende Übersicht zeigt noch einmal die bis jetzt vorhandenen Daten- und Kontrollstrukturen des Projektes:
Wie wohl jedes Projekt steht auch dieses unter Zeitdruck und mußte mit der Anwendung beginnen, bevor alle Entwicklungsarbeiten der Softwarewerkzeuge abgeschlossen waren. Und immer wieder werfen neue Verhältnisse in den Tagebüchern Fragen auf, für die XML-Erfassungs-Konventionen und Verarbeitungsprozeduren entwickelt werden müssen. Bisher haben sich XML, die TEI-basierte DTD und die Arbeitsumgebung stets als fexibel genug für alle neuen Anforderungen erwiesen.
Insbesondere folgende Vorteile der Lösung sind hervorzuheben:
Oben wurden bereits die Schwachpunkte der verwendeten Software-Werkzeuge beschrieben, die zum Glück weitgehend umschifft werden können. Es bleiben jedoch einige offene Fragen und kritische Anmerkungen:
key-Attribute zugewiesen, also alle Namen identifiziert sind, könnte
das "deduktive" Register der EDDA-Datenbank einem "induktiv" (mit TUSTEP) gewonnenen Register aus dem
tatsächlichen Text gegenübergestellt und automatisch verglichen werden. Damit wären
formale Eingabefehler bei den Datenbankschlüsseln zumindest nachträglich
aufzuspüren.Das theoretische Bekenntnis zur strukturierten Datenhaltung mit XML ist im Projekt zur Edition des Tagebuches von Harry Graf Kessler endlich praktisch umgesetzt worden. Die Erwartung zu Projektbeginn, aus einer Textbasis alle gewünschten Ausgabeformen algorithmisch erzeugen zu können, hat sich spätestens mit der TUSTEP-Satzausgabe erfreulich bestätigt. XMetaL als zentrales Werkzeug für die Datenpflege bietet mit seinen verschiedenen Sichten auf den Text einen idealen Migrationspfad von WYSIWYG-Gewohnheiten zu sauberen Strukturen. Damit wird der Einsatz leistungsfähiger Werkzeuge wie TUSTEP möglich, ohne die Vorteile der Windows-Welt (komfortable Oberfläche, Integration per Javascript/WSH) aufgeben zu müssen. Das Datenformat auf der Basis sachgerechter, offener Standards (TEI, XML) verspricht die notwendige langfristige Verfügbarkeit und erlaubt es, die Versionsentwicklung der beteiligten Software nicht als potentielle Quelle von Inkompatibilitäten, sondern als willkommene Chance der Fehlerbehebung zu betrachten. Der erfolgreiche Einsatz von XML ist somit nicht nur als Prototyp für vergleichbare Editionsprojekte geeignet, sondern auch als Vorgabe für die Sammeltätigkeit des gesamten Deutschen Literaturarchivs, soweit elektronische Texte betroffen sind.
aus: Protokoll des 82. Kolloquiums über die Anwendung der EDV in den Geisteswissenschaften am 14. Juli 2001